
Savvy organizations know that business growth and success are intrinsically linked with an effective strategy for managing data. But as the big data momentum builds, more questions are raised. In this post, I’ll answer five of the most important ones.
How can I sift through the abundance of data to focus on what really matters?
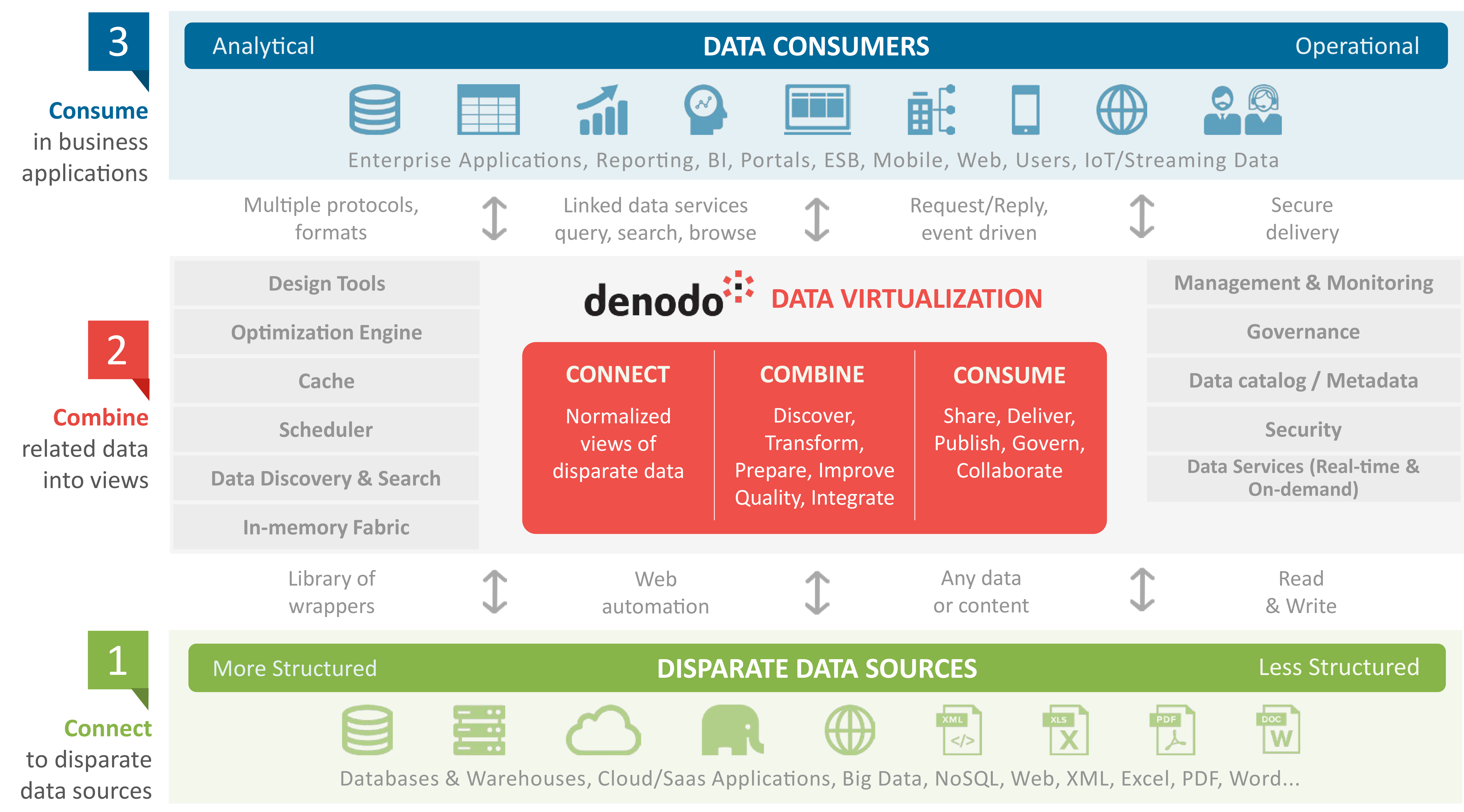
Data virtualization simplifies the consumption of big data by making it available from a single virtual layer that connects to disparate data sources. Data virtualization acts as a magnifying glass to the big data pile, helping you to focus on only the data that is relevant to you.
How can I gain value from my data, faster?
Batch oriented data integration methods like ETL (extract, transform, load) processes no longer suffice, due to the significant delay involved in replicating the data. Data virtualization does not involve physically copying and moving the data, so the data is available to business users in real time.
How can I ensure that the whole team has access to business intelligence?
Keep it simple, by creating an abstraction layer: data virtualization hides the underlying complexity of data processes from the business user. This enables companies to empower business users by giving them self-service access to the business intelligence they require.
How can I use data to improve decision-making?
Self-service access to business intelligence, in turn, directly improves the efficiency of the decision-making process. If business users no longer need to rely on the IT team for data insights, the whole process will be sped up.
How can enterprises provide governance across all their data?
Who can touch which data? How can enterprises track how data has been modified from its original state? How can enterprises protect customers’ personal data? All of these questions become all the more important in light of the GDPR regulations, which will go into effect next year. Data virtualization can help organizations seamlessly comply with the GDPR, and any other set of regulations, due to its data tracking and lineage capabilities.
Data virtualization is the answer:
For more information on how data virtualization is addressing the questions raised by the big data movement, visit www.denodo.com/bigdata

- Is Bad Data Causing Bad Decisions? Learn from Indiana University - February 6, 2018
- Migrating to the Cloud? 6 Important Pre-Flight Checks Before You Take Off - January 22, 2018
- Data Virtualization Is The Answer to Your Big Data Questions - December 20, 2017
What is the difference between data virtualization as described here vs accessing the data directly or loading it directly from the source?
I am not to clear on the advantages provided? Seems like the only advantage is just using one language or one program – the so-called “unified” layer?
Hi Pierre,
When connecting directly to the source, like you do with data virtualization, you are avoiding the latency issues associated with replicating and moving the data. By connecting to the data through this unified layer – you get total visibility of all your data and most importantly, this access is in real-time.
I hope this helps.
Amy