
Consider a business scenario in which a user wants to determine the sales per month at a product level, and the filter conditions vary for different cases and across different users (So it would require multiple ad hoc queries). If the sales and product data are located in different data sources and the sales data is comprised of millions of rows, then every time the required data is fetched by querying sales data, since it would require a join with the appropriate table, joining product data, and then aggregating the data, it would result in a huge amount of data being transferred over the network and a much slower query, which would consume a lot of resources and impact overall performance.
To avoid these kinds of scenarios and improve query performance by reducing the amount of data transferred over the network and avoided the repeated querying of big tables, Denodo Platform 8 offers a new feature called Summary view.
- Summaries store common intermediate results that the query optimizer can then use as a starting point to accelerate analytical queries.
Summary views make use of smart caching techniques to boost query execution. Summary views are usually used when users execute multiple ad hoc queries joining and aggregating different views in a self-service way.
The main goal of using Summaries is to minimize data transfer, processing at the data source level and the Denodo Platform level. For that, it is advisable:
- To store the Summaries in a database close to the Denodo instance
- To store Summaries in a data source close to the actual data
- It is also recommended to:
- Use Indexes
- Enable and gather statistics for the view
The Denodo execution engine will decide to use Summaries when:
- The views being accessed by the original query are present in the Summary view
- The join condition of the original query matches the join condition of the Summary view
- Even if the join condition does not match, it would be sufficient if the field is being projected in the Summary view.
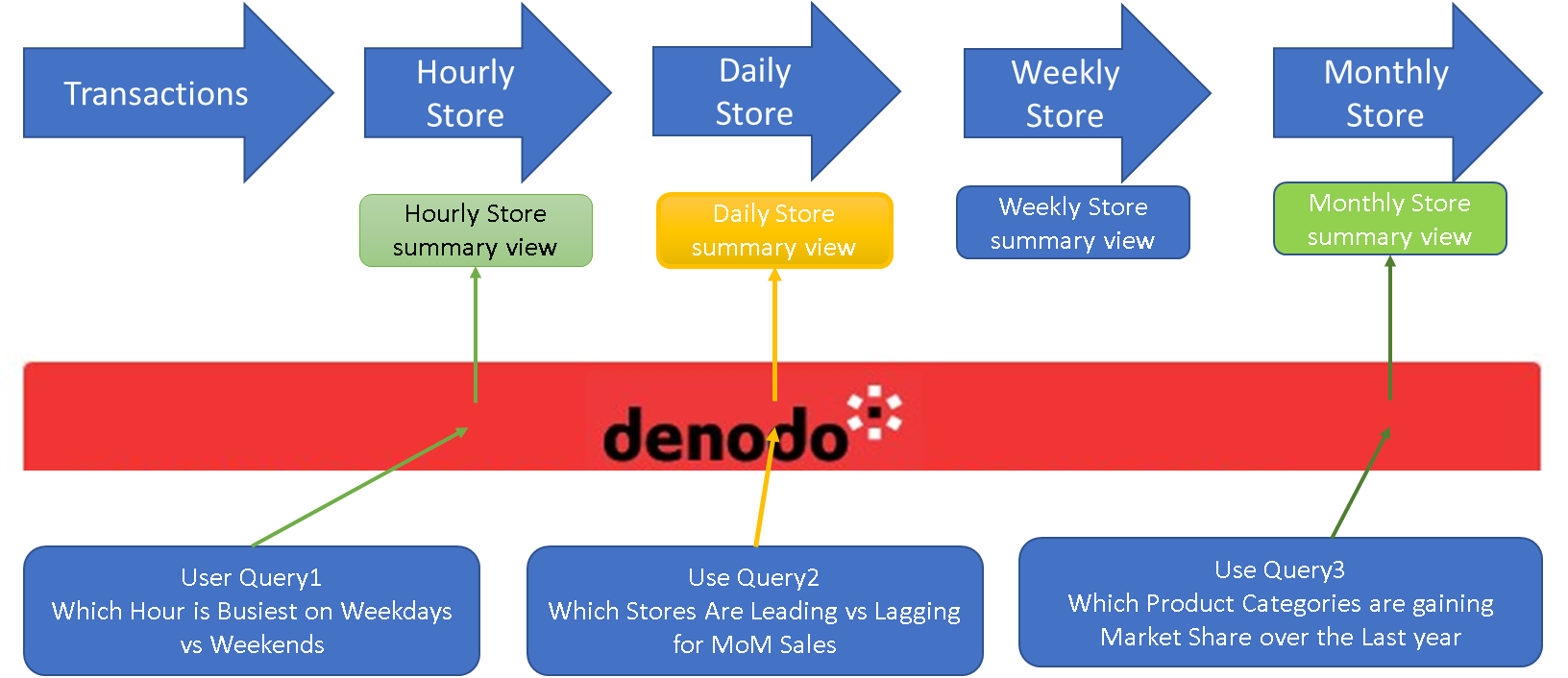
A. Use cases
- Self-service scenarios (ad hoc queries)
The most important use case for Summary views is the one requiring self-service queries on a logical data warehouse. This is a situation in which users request data that does not have to be in real time and when they will access canonical views.
In this environment, Summary views increase query performance and reduce the load of the data sources involved in the queries.
- Hybrid environments with cloud systems:
In the journey to the cloud, some users will probably need to combine data that is still on-premises with data that is already in the cloud.
- Hybrid environments – multi cloud system:
When there is data stored with different cloud providers, it is a good idea to have one or more Denodo servers on each cloud system so the data is processed as close to the data as possible and minimizes data transfer. In this scenario, it is also useful to create Summaries on each location, containing common combinations with data in other locations. This way, users can avoid having to access the other cloud or on-premises system when it is unnecessary.
B. Creating Summaries
There are two ways to create Summaries:
- Using the administration tool wizard.
- Using the CREATE SUMMARY VIEW command.
When a Summary view is created:
- The execution engine creates a table in the selected JDBC database.
- It executes a VQL query and inserts data into the created table (Bulk data load can also be used for data insertion if the underlying database supports it).
C. Manage Summaries (Refresh Data)
Summary data must be kept up-to-date. Summaries can be refreshed frequently in two ways:
- Using the REFRESH button in the Summary wizard
- Using the REFRESH VQL statement
The data can be automatically refreshed by creating a job to refresh it and using the same job scheduler to make it run at a regular frequency.
D. Benefits:
- Remarkably faster queries
- Save time, cost, and resources
- Transparent to the user
Illustrative Use Case
Suppose a user wants to run an ad hoc query to determine the sales (the sales amount) at the product level, per month, for the year 2018. The two data sources are:
- sales – Contains customer sales transactions (derived from base view bv_customer_sales and bv_customer_salesorder)
- product – Contains product details (the corresponding base view is bv_products)
QUERY:
Select txn_year as txn_year, txn_month, product_name, sum(price) sale_amount
from sales sal, product prd
where sal.product_id = prd.id and sal.txn_year = 2018
group by txn_year, txn_month, product_name

Creation of Summaries
Now let us create a summary view (s_customer_sales) using the query
SUMMARY QUERY (s_customer_sales):
select txn_year as txn_year, txn_month as txn_month, product_name as product_name, sum(quantity) as quantity_sold, sum(price) as sale_amount
from sales sal, product prd
where sal.product_id = prd.id
group by txn_year, txn_month, product_name;

Now, with Summary view the ad-hoc query executed by consumer is analyzed by optimizer, and it rewrites the query as follows:
select txn_year txn_year, txn_month txn_month, product_name, sum(sale_amount) sale_amount
from s_customer_sales
where txn_year = 2018
group by txn_year, txn_month, product_name;
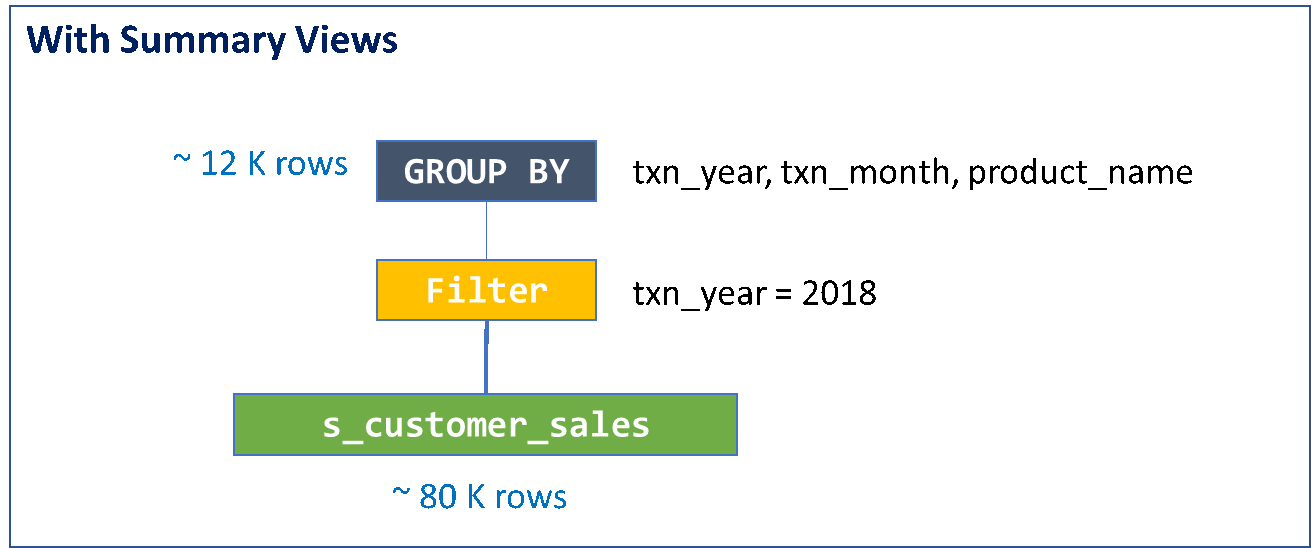
As seen in the picture above, the optimizer identifies the presence of Summary view, satisfying the criteria, so instead of fetching data from the data source it extracts the data directly from Summary view (s_customer_sales). The query now runs against Summary view, which is a very small amount of data compared with the data at the source. The data-fetching process will therefore be very fast, and only a small set of data is transferred. Summary views increase query performance and reduce the load of the data sources involved in the queries.
A Closing Note:
- Summaries are only supported in JDBC data sources.
- These views can only be created, modified, or dropped by admin users.
- Admins must also ensure that their credentials supplied in the JDBC data source provide them with the privileges to create, edit, or drop summaries in the database.
- Optimizations such as summary rewrite, user summaries for query acceleration, data movement, and automatic simplification of queries must be enabled in the Virtual DataPort server.

- Smart Query Acceleration Using Summaries - November 4, 2021