
What is OData?
The Open Data Protocol (OData), currently in version 4, is an open data exchange protocol maintained by the OASIS Consortium as a standard. Originally proposed by Microsoft in 2009 (and maintained by them until version 3), it defines a series of syntax rules, formats and best practices for building HTTP RESTful APIs using a more convention-based approach than is normally used for this kind of services, which allows an easier client-server integration.
With the sponsorship of OASIS and Microsoft and its adoption by several key players in the corporate data ecosystem like SalesForce, SAP or Oracle, the OData standard is becoming more and more a part of the conversations on data interchange in the enterprise these days.
Down to the technical detail, OData HTTP requests are allowed to specify complex queries on data through a standardized URI syntax (selections, projections…), and data payloads can be transferred in both XML(Atom) or JSON formats. OData also understands the existing associations between the different data types (entities) in your database and allows the easy navigation of these associations in OData queries.
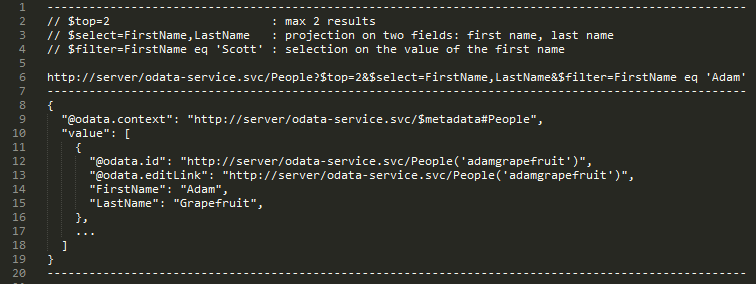
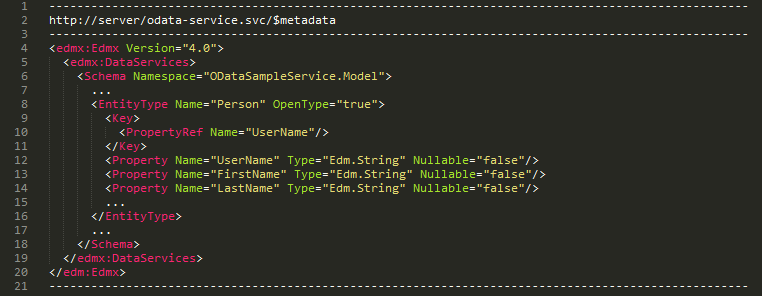
Also, OData services offer full metadata describing the entities and operations available, which enables both the creation of fully-featured generic clients and tools, and also easy integration from existing data visualization tools, reporting software, spreadsheets and a load of data management applications, both end-user and middleware.
From the standpoint of data virtualization, OData is a very useful concept not only because it offers the possibility to retrieve data from data sources exposing OData endpoints in a standardized way, but also because it allows data virtualization systems to offer OData endpoints that will enable other systems in the organization to consume virtualized data very easily. All of this without the need to exchange a previous “contract” or specific information on the data API, other than the URL of the endpoint and the version of the OData standard being used.
OData as a data consuming source
By supporting OData data sources, a data virtualization middleware system is able to integrate data coming from a larger variety of systems, and benefit from at least two interesting advantages.
First, that thanks to the rich metadata offered by OData services, integration can always be complete and univocal with regard to data types, restrictions and relations. The OData Service will always offer to the data virtualization system the full metadata of the data that it is returning, and this should help the DV system automatically create the required structures for representing this data in a 100% precise way, without the need of making admins rely on manually-written API documentation at any point in the process.
Second, that thanks to the way OData servicies explicit associations between their entities, the data virtualization system can attain a deeper understanding of the semantics and logical relations among data entities, which in turn offers the opportunity to better integrate the source’s semantics into the higher-level data semantics and logical relations of the virtualized database as a whole.
OData as a data publishing interface
In similar lines to the use of OData as a data source, the benefits of offering virtualized data from a DV system in the form of an OData Service are easy to spot: easier integration, better data semantics.
In practice, this means that data virtualization systems that offer their data through OData will get the capability to be queried from generic clients that may need to know no other specifics about the data published by the DV system than the URL of the endpoint and the syntax and formats of the OData standard. This means a large collection of enterprise software, from reporting to business management and from in-house to SaaS, can easily extract profit from data virtualization with minimum integration efforts.
- Zero-Code GraphQL API Creation with the Denodo Platform - May 13, 2020
- Using Data Modeling Tools for Top-Down Data Virtualization Design - January 3, 2018
- Supporting Geospatial Data in Data Virtualization Environments - September 27, 2017