
This blog was penned by guest blogger, Thibault Perier, Data Scientist from Astrakhan Innovation Management.
A typical company manages many disparate data sources, representing volumes that are only growing larger over time (all whilst big data repositories expand in capacity and as media continues to become digitized) resulting in a multiplication of sources, often redundantly. This makes collecting data for analysis a time-consuming proposition.
The solution is data virtualization. This approach unifies multiple sources under a single layer of abstraction, which includes semantics, so that applications, reporting tools, and end users can access data without worrying about its location, structure, origin, or source. Welcome to the world of self-service data access.
To set up this level of abstraction with data virtualization, we create views of tables or sources that we want to analyze, and we group them into one, even when the tables come from different sources (for example, we can combine data from MySQL, CSV files, and Hadoop). A single point of access provides a window into all the data across a company, from structured data to completely unstructured data.
With data virtualization, companies can:
- Unify data security across the whole company (and even outside the company) via groups that have designated access privileges.
- Increase the agility of development teams when launching data integration projects.
- Decouple data consumers from the complexities of the underlying physical structures, to eliminate the impact of changes to users’ day-to-day operations.
- Provide operational data in real time, processed, cleaned, and formatted to meet specific needs.
Data virtualization provides unified access to a wide range of big data and cloud repositories, and offers features such as provisioning and governance. The diagram below clearly illustrates the way the Denodo Platform mediates between data sources and their consumers. The Denodo Platform requires trained teams that can operate at both a functional level (semantics) and a technical level (managing the connection to sources), but the platform comes with a wide range of connectors that facilitate this effort.
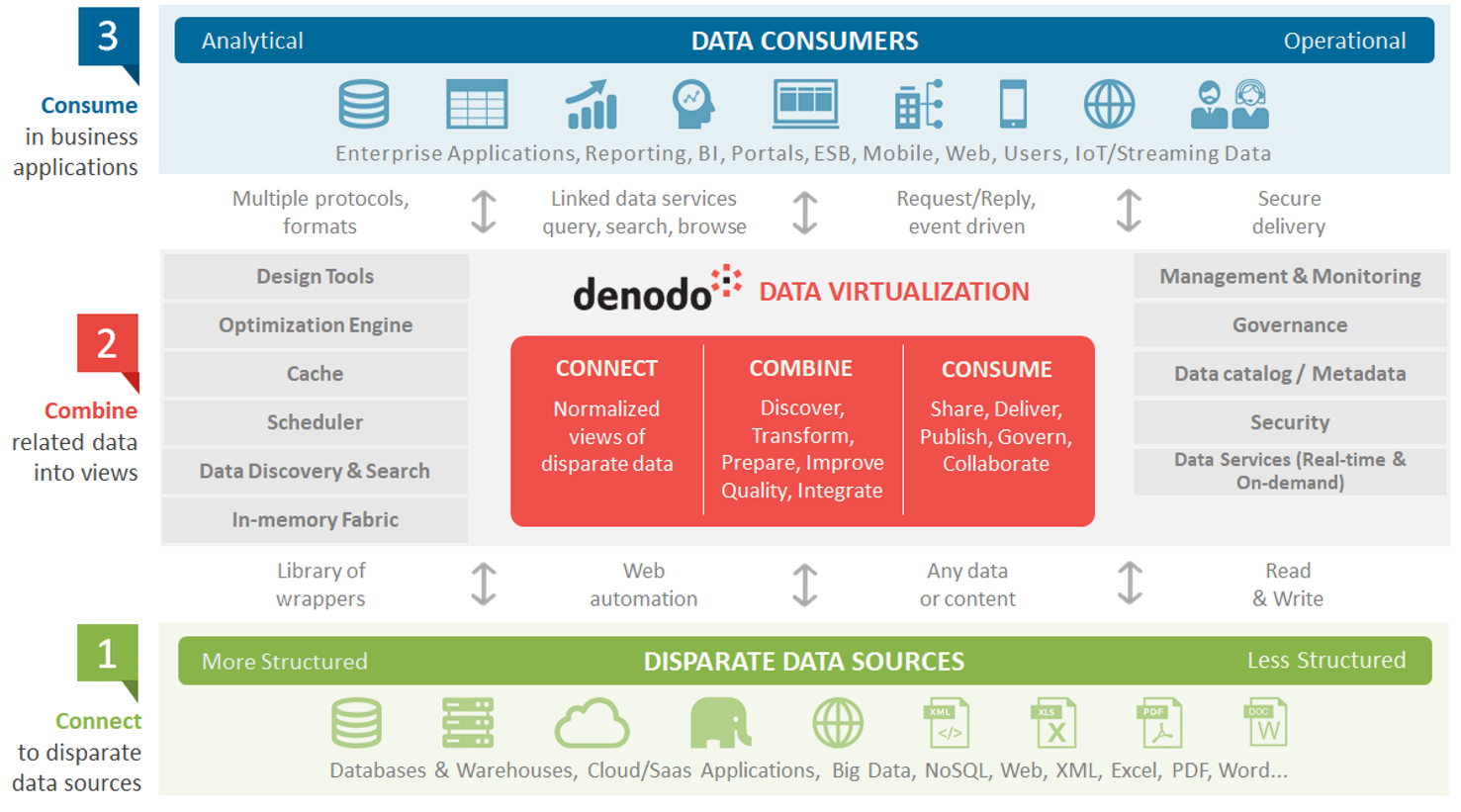
Data virtualization is therefore fully capable of replacing an ESB-type solution, since it offers advanced functions. Natively, for example, the Denodo Platform can offer:
- The ability to model data, global search, and data lifecycle management.
- Intelligent caching to improve real-time performance and minimize data flow.
- Query optimization features, supported by a dedicated (but proprietary) language.
- Robust security with user/role definition (or import from LDAP/AD), finely structured access restrictions (up to the data cell level), selective data masking, and custom security policy enforcement.
- Complex, real-time analytics and integration with leading computing platforms in memory and in the cloud.
Note that via APIs, the platform can also expose services into the wider ecosystem.
Data virtualization can have a strong impact on the governance and organization of big data centers-of-competence, positioned between data sources, on the one hand (processed and manipulated by data engineers), and data consumers on the other (including data scientists), streamlining data manipulation and simplifying security.
Data virtualization might also be able to extend the role of data engineers, especially as it offers them quite advanced functionality:
- In design-time: A centrally defined business glossary with advanced data lineage, change impact analysis, and catalog search capabilities.
- In run-time: End-to-end performance monitoring to detect bottlenecks, with the ability to trace all operations.
Data virtualization disrupts the way data is used and analyzed in the enterprise, dramatically reduces the time spent on transferring, cleaning, and processing data. It will greatly benefit any company preparing for a future characterized by technological, organizational, and procedural change.
- Connect the Dots, to Better Serve the New Customer - March 28, 2018
- Data Integration, Made Easy (and Fast!) - February 22, 2018
- Easy Access to Big Data Insights - January 25, 2018
Data integration is important for modern business because it has the ability to improve collaboration and facilitate omnichannel customer experiences