
It seems at present there is huge amount of hype on big data and the concept of a data lake related to data virtualisation. Already however there is confusion as to what a data lake is with multiple different definitions ranging from a centralised data store on Hadoop to a Logical Data Lake consisting of multiple data stores that include cloud storage, Hadoop or multiple Hadoop clusters, Data Warehouses, NoSQL data stores, Master Data Management (MDM), Reference Data Management (RDM) systems and enterprise content management systems.
Obviously a centralised data lake consisting of a single physical data store like a Hadoop Distributed File System (HDFS) is much easier to manage than a logical data lake but for most of my clients, they are trying to manage a logical data lake and if you can manage this, you can certainly manage a centralised physical data lake. Figure 1 shows the logical data lake with data virtualisation highlighted.
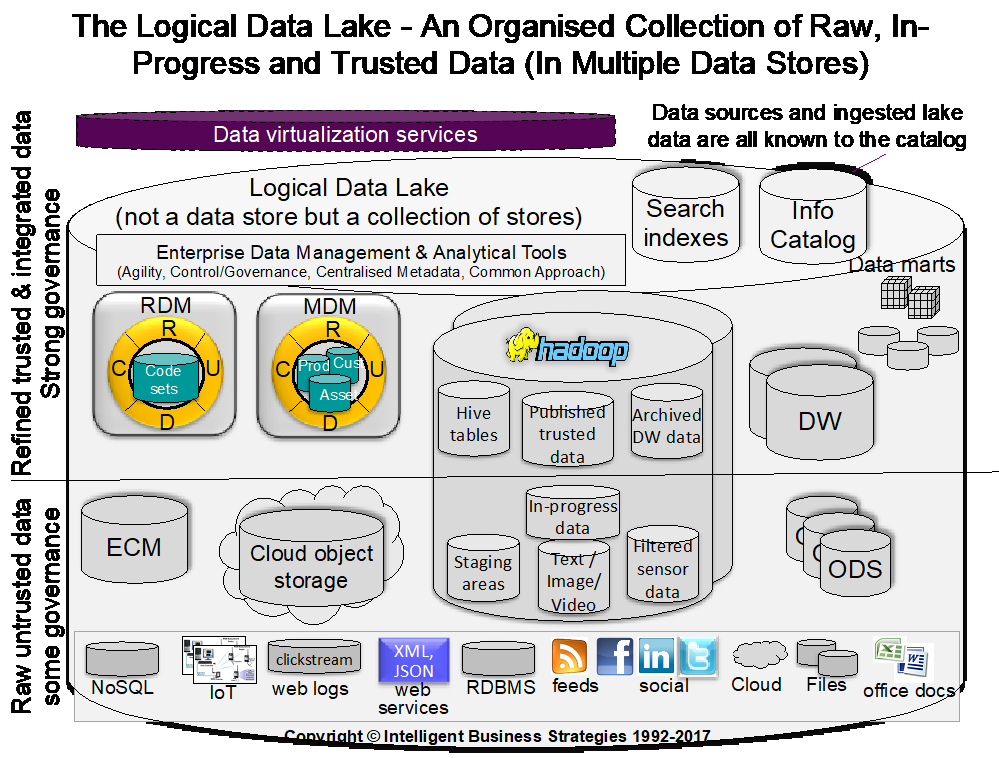 Figure 1
Figure 1
So what exactly is the role of data virtualisation in a data lake? The obvious answer is to simplify access across multiple data stores. I don’t want to go into this in any more detail as we have already seen blogs on this in the form of Logical Data Lakes and Do Data Scientists Really Ask For Physical Data Lakes?
In my opinion it goes way deeper than just simplifying access. For this reason, I would like to look at data lakes in more detail and drill down into areas where data virtualisation technology like the Denodo Data Platform can be used. Figure 2 shows how you can organise a data lake into zones. Depending on whether you have a centralised or a distributed logical data lake, the way in which you managing these zones may vary. The obvious way is via tagging so that you can ‘label’ data as being in a certain zone.
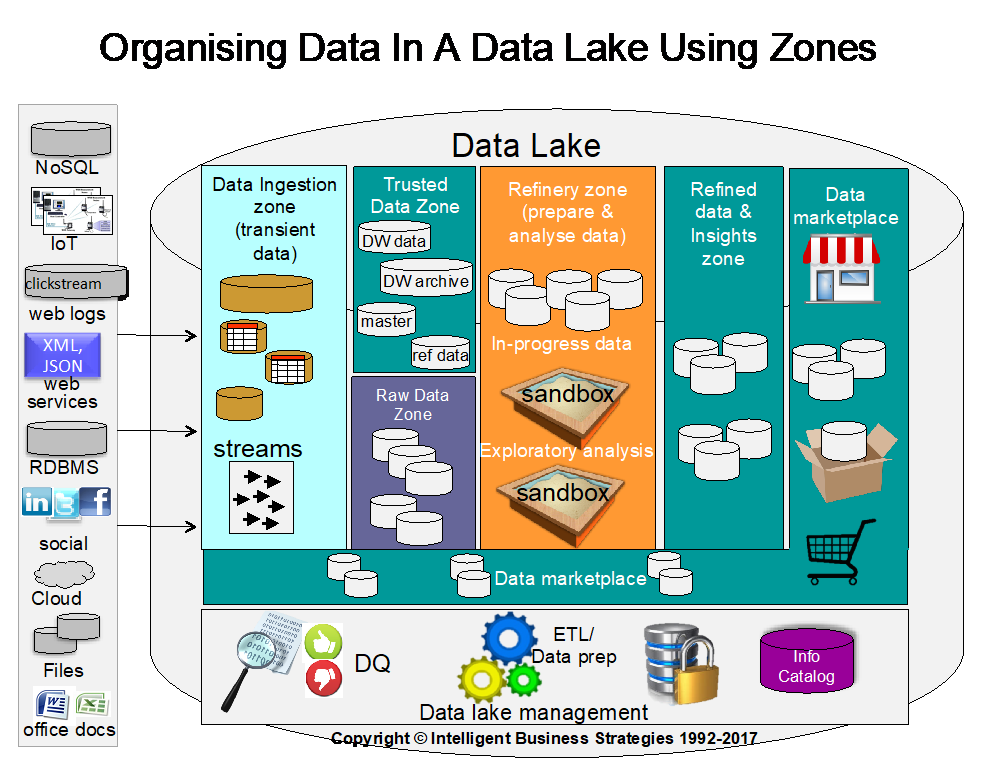 Figure 2
Figure 2
The key question is what is the role of data virtualisation within each of these zones? Let’s take a look. As you can see we have the following zones:
- Data ingestion zone
- Raw data zone
- Trusted data zone
- Refinery zone
- Refined data and insights zone
- Data marketplace
Typically processing will flow left to right through these zones.
Figure 3 shows where data virtualisation can be used to improve agility and reduce data copying in specific zones.
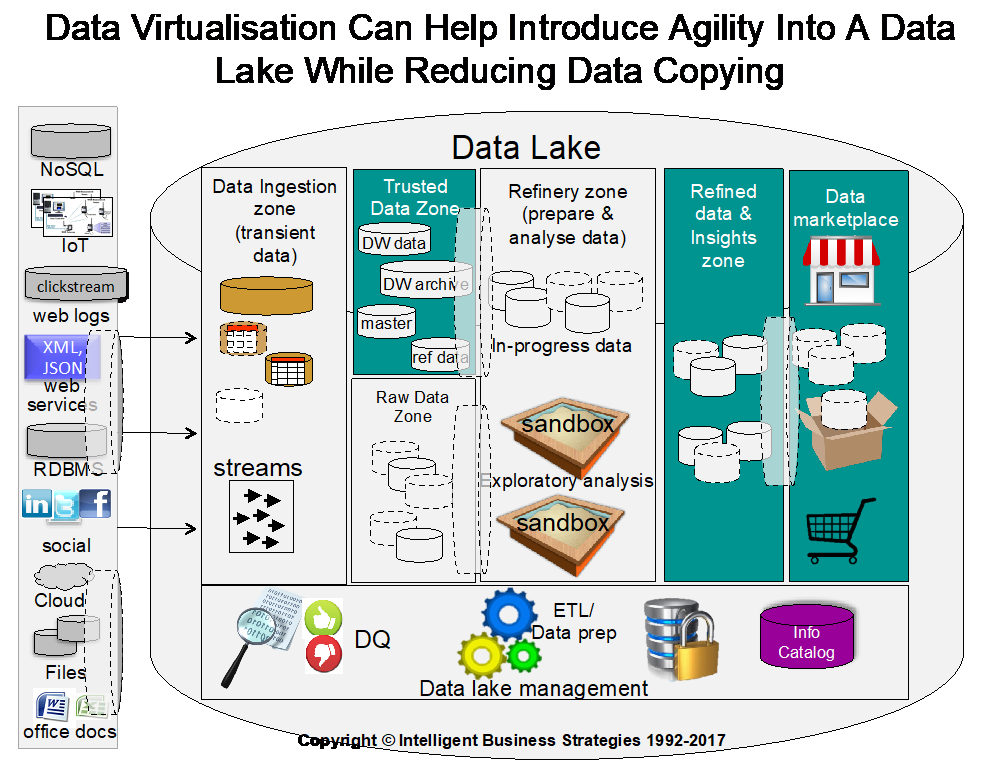 Figure 3
Figure 3
Within the ingestion zone some structured understood data sources can be virtualised to simplify ingestion from many data sources and to limit the data being ingested to only that of interest. That means within the ingestion zone there may be some virtually ingested data. This may be particularly useful if data cannot be moved for legal reasons (e.g. GDPR).
The raw data zone is approved ingested data – data that has been ‘signed off’ for use within the enterprise by qualified data specialists who are able to understand the raw data being ingested once automated discovery, profiling and cataloguing of data has occurred. Therefore the raw data zone may have both physical and virtual datasets.
Data virtualisation also has a role to play in the trusted data zone where trusted, already cleaned and integrated master data, reference data and historical transactional activity data is stored in MDM systems, RDM systems, data warehouses and archived data warehouse data stores. Here, there may be multiple virtual views of trusted master, reference or historical DW data. Also there may be virtual views of raw data. The objective here is not to put barriers in the way of data scientists but to make it easier for them to access data and speed up self-service data preparation for input into analytical models being developed in a data science project. It also can be used to protect sensitive data in the trusted data zone or in the raw data zone and police what data scientists can and cannot see. So there is both a governance element to this and a productivity improvement element to justify why data virtualisation makes a difference.
Within the data refinery zone, data from virtual and physical datasets can be processed and integrated to provide data needed for data warehouses and to provide the input attribute data needed to train predictive models using supervised machine learning for example.
The output from refining data is trusted, prepared and integrated data and/or insights, which again could be a mix of virtual and physical data sets in the refined data zone. At this point the data needs to be mapped into a common business vocabulary of commonly understood business data names before being published in a data marketplace (an areas on an information catalogue) for other business users and applications in the enterprise to find, consume and use.
However there is one final place where data virtualisation can be used in a data lake and that is in the data marketplace. If people find and see trusted data that they need in the data marketplace, the danger is that they all want to download it. In other words they want to pull it all ‘to the edge’. For many companies that is the last thing that they want to happen – for all kinds of reasons. First, if the data is now trusted and governed, why send out datasets all over the enterprise to places where you lose track of it again and aren’t able to govern it. Also, how do you stop people creating copies of data that results in compliance violations? The answer is not to physically provision data as a service but to provision data as a service virtually and so prevent ‘runaway copies’ occurring, prevent unauthorised access to data and prevent compliance violations caused by data being taken outside of a jurisdiction when it is not permitted to do so.
Looking at this, the role of data virtualisation is a data lake is very important. It improves agility, and self-service productivity. It also introduces governance and prevents governance of trusted data from spiralling out of control.
- Enabling a Customer Data Platform Using Data Virtualization - August 26, 2021
- Window Shopping for “Business Ready” Data in an Enterprise Data Marketplace - June 6, 2019
- Using Data Virtualisation to Simplify Data Warehouse Migration to the Cloud - November 15, 2018