
Data lakes have captured the imagination in the past few months. The idea of having all of your data stored in a ‘lake’ – available to all and sundry – is very appealing to both data architects and to the business users of the data. Not having to integrate data from different data repositories and accelerating data usage sounds like a wonderful idea to everyone – and that’s if you already know what data you need and where to find it! The promise of Big Data is that you can look for correlations and relationships between data entities that you didn’t know existed…largely because your data was scattered around different repositories and you never had the ability to discover these correlations and relationships.
So, data lakes sound like a great idea. But what is the reality behind implementing a data lake in a typical organization? Depending upon who you listen to, a data lake can be as simple as firing up a Hadoop cluster and moving your data into HDFS – the Hadoop cluster becomes your data lake. However, the reality is much, much more complex than that. Most organizations already have numerous data repositories – data warehouses, operational data stores, data stored in files (e.g. log files, Excel spreadsheets, etc.), and so on. It is simply not realistic to load all of this data into a central repository (the ‘data lake’) and give everyone access to it. If you also add in the so-called Big Data – clickstream data, sensor data, data from mobile devices, data from social media, etc. – then the picture gets even more complex. Now you have data of different formats and structure, different levels of quality and veracity, with different security and privacy requirements and you don’t want to simply mix them all together into a central data lake – that’s how the data lake becomes a data swamp! You don’t want to mix your cleansed and verified historical reporting data with unfiltered data coming from, say, mobile devices.
However, this doesn’t mean that the concept of a data lake is wrong – or that you can’t take advantage of a data lake. Using Data Virtualization, it’s possible to leave the data in its current repository, such as a data warehouse, Excel spreadsheet, operational database, or even Hadoop, and use the Data Virtualization layer to create a virtual – or logical – data lake. In essence, each existing data repository acts like a small data lake (a ‘data pond’?) and the Data Virtualization layer provides access to each data pond to create the overall logical data lake. This is illustrated in the diagram below.
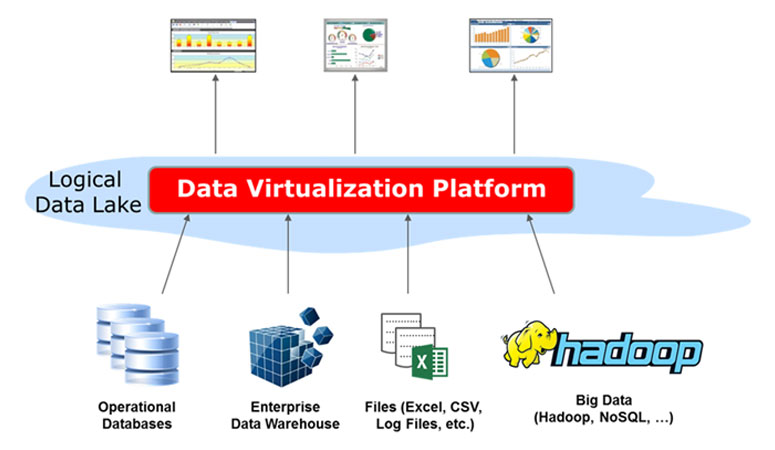
Because the data remains in its original repository and is queried on-demand by the Data Virtualization layer, no mass copying or replication of data into a central data lake is required. However, to the consumers of the data – for example, BI and reporting tools, applications, and so on – the data looks like it is a single data source, i.e. an integrated ‘logical’ data lake.
Using Data Virtualization in this way allows organizations to move towards a data lake strategy, realizing the benefits of a data lake without going through the turmoil of creating a physical data lake. The Data Virtualization layer allows administrators to control access to only the data that users need and provides data governance and usage auditing. All of this…without needing to copy data to a new centralized mega-repository, or create a new security mechanism, or worry about mixing clean data and data of unknown quality and veracity.
With the logical data lake, users requiring reports using trusted data can access the information that they need, while data scientists can build an analytics sandbox to mix new data (e.g. in Hadoop) with historical data, analytical data, and even local data to extract the key insights that can add value to the business.
Over time, the organization might decide to build a physical data lake and start moving data into the new repository. This transition can be hidden from the users by the Data Virtualization layer, allowing for the seamless and phased migration from a logical data lake to a physical data lake – at the pace (and with the ‘success’ checkpoints) that feels comfortable for the organization.

- The Energy Utilities Series: Challenge 3 – Digitalization (Post 4 of 6) - December 1, 2023
- How Denodo Tackled its own Data Challenges with a Data Marketplace - August 31, 2023
- The Energy Utilities Series: Challenge 2 – Electrification (Post 3 of 6) - July 12, 2023
Nice clean description Paul.
I’d like to see some further posts about aspects of the framework that organisations need to put in place to move towards this pattern.
I’m thinking of things like, how to establish a more centralised ownership and governance model (even logical) to ensure that current physical owners and custodians can understand their new responsibilities to the formed logical lake; how metadata and data catalogue services can help plan the transition of entities across to the lake and maybe even how further services layers can be envisioned/conceptualised to allow organisations to first establish the basic model and then mature that with the creation of increasingly rich services.
I’m sure by now you guys have experience of all this and it would be good to have a post that provides the basic framework (even a diagram).