
2018 is exactly thirty years since I published the first data warehouse architecture. The core concepts of the architecture remain strong and viable. However, the evolution of both business needs and technology solutions over the intervening decades has led to a whole new set of architectural considerations and concepts such as “logical data warehouse”, “data lake”, “enterprise data platform”, and more.
These concepts are often presented as competing approaches or replacements for data warehousing, leading to much confusion among businesses trying to wring value from data. This misunderstanding is most easily eliminated by focusing on one key technology—data virtualization—which allows builders of warehouses (and other data management systems) to offer integrated access to data distributed over multiple physical platforms.
To understand the importance and central role of data virtualization, we need only condense the above-mentioned business and technology evolution into a single sentence: Business requires and will continue to require ever more data, more quickly and more agilely, from more varied sources, both internal and external, than ever before. Put like that, the idea of trying to force all the data the business may ever need into one store before business people can use it for gaining insight is complete nonsense.
Does this negate the idea of a data warehouse? Of course not! There remains a subset of data for which a single, reconciled store makes sense. That subset is called core business information: the set of strictly defined, well-managed and continuously maintained information that defines the business—its identity, activities and legally relied-upon actions—from its time of inception to the present moment. This is a smaller volume of data than stored in most modern data warehouses. And even this set of data may be divided and stored over more than a single platform. Older, historical data seldom needs the same level of access as more recent data and may well be moved to cheaper or slower storage.
No matter how you look at it, the data needed by a modern digital business already exists on multiple platforms and will increasingly do so. Business people need to access these multiple platforms transparently from their one favored tool. They also need to be able to combine or join data from these platforms into a single result. The only technique that can do this is data virtualization.
Simply defined, data virtualization takes a single query—be it from a business user or an app—and splits it into its constituent parts, sending the individual parts to different data platforms, receiving and combining the individual results into the required answer. And it does all this in real-time.
The concept is not new. Indeed, it dates to the early 1990s, when it was often limited to relational data on distributed platforms and called data federation. Since then, data virtualization has been extended in scope, function and power until it has become the mature and comprehensive platform offered today by Denodo as the accompanying diagram, which shows the scope and extensive functionality of the Denodo platform.
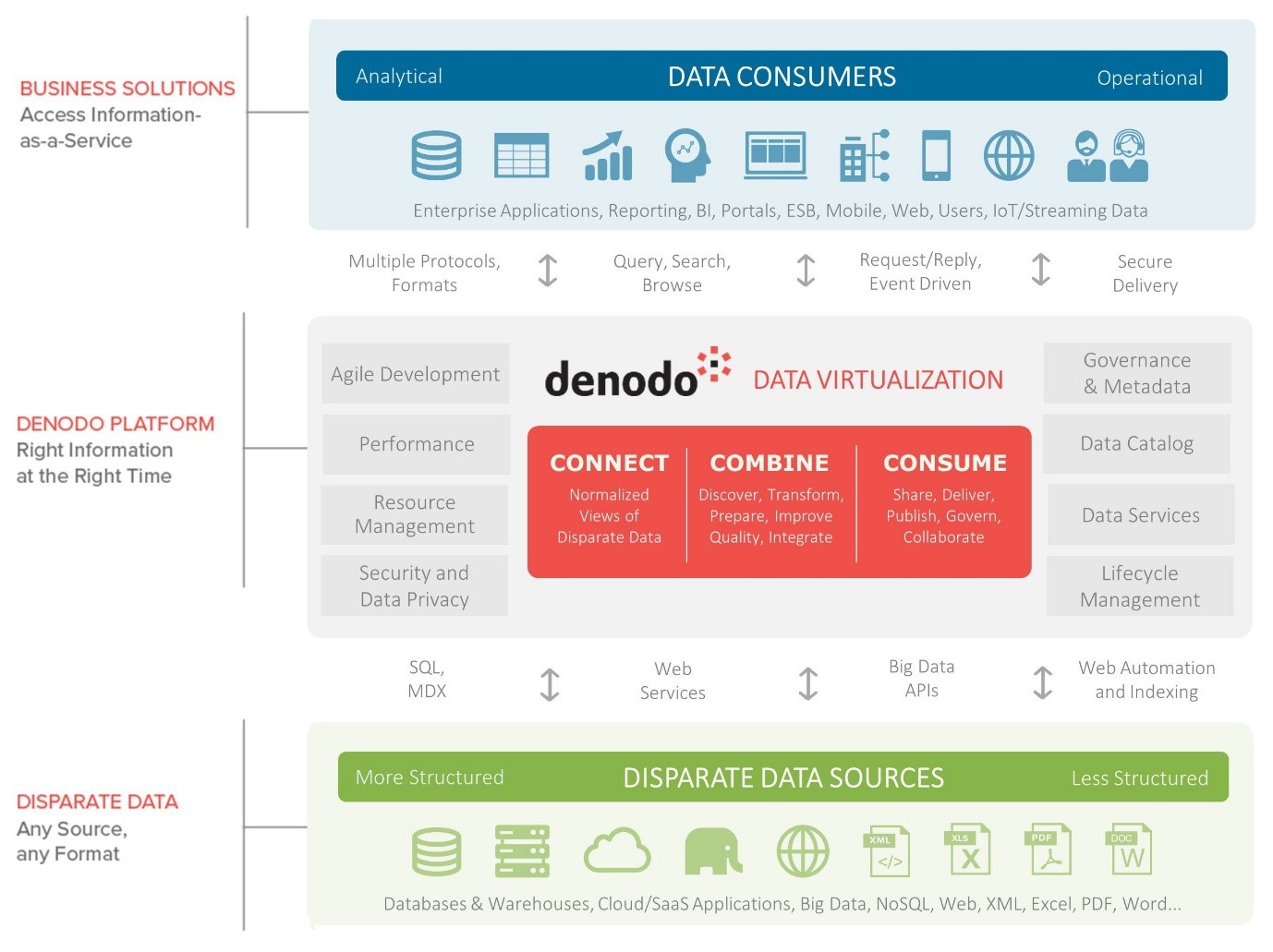
However, rather than work my way through this diagram, I believe it will be far more informative for readers to examine data virtualization from the point of view of the three most common use cases that apply to data warehousing and related approaches to delivering insight to business people. I’ll dive deeper into these cases over the next three posts but first: a sampler here of where we are going.
One of the longest standing use cases for data virtualization in data warehousing relates to data freshness. If you need up-to-the-minute data as part of a query, copying it from an operational source via ETL (extract-transform-load) technology into the warehouse is unlikely to offer the timeliness needed by the business. In my next post, I show how data virtualization goes straight to the source for real-time results.
Another timeliness-related use case refers to development and maintenance time. Data warehouse projects traditionally have a poor reputation for rapid delivery of results, whether for the initial build, extensions of scope, or even ongoing maintenance. Solutions have ranged from narrowly scoped data marts to the now ubiquitous data lakes. In the third post of this series, I look at how data virtualization offers new levels of agility in design, development and maintenance of systems consisting of a mix of warehouse, marts and data lakes.
Over the past decade, businesses have faced a huge influx of data in a wide variety of structures—ranging from audio and video through free-form text to hierarchical and graphical data. What these structures have in common is their limited suitability to relational databases and their consequent management in many different stores. In the final post of the series, I examine how data virtualization allows us to mix and match best-of-breed storage technologies with business people’s needs to see and manipulate all these stores as if they were one.

- The Data Warehouse is Dead, Long Live the Data Warehouse, Part II - November 24, 2022
- The Data Warehouse is Dead, Long Live the Data Warehouse, Part I - October 18, 2022
- Weaving Architectural Patterns III – Data Mesh - December 16, 2021