
Over the years I have seen how data virtualisation can simplify data access and significantly improve agility. Given all the benefits this brings, I would most certainly recommend any organisation to add data virtualisation software to their toolbox – particularly in analytical environments. However it’s not often you hear about another side to data virtualisation, which is the ability to provide virtual data sources to things like ETL processing. So I thought I would look at a few scenarios where this can yield significant benefit. I would like to look at three uses of virtual data sources. These are in the cases of:
- Merger and acquisition
- To stabilise data warehouse ETL processing
- To simplified self-service data preparation
Merger and Acquisition (M&A)
It is a daily occurrence these days to see announcements of two companies merging due to an acquisition. So much so that we never give it much thought unless of course you are on the inside dealing with the consequences. In these kinds of situations, everything is on the move and everything needs to merge if true integration is to happen. That includes both operational transaction processing (OLTP) systems and analytical systems like data warehouse and data marts. If you have ever been involved in anything like that you will know how challenging it is. But despite the complexity, the business demands it is done quickly while still being able to function as a business.
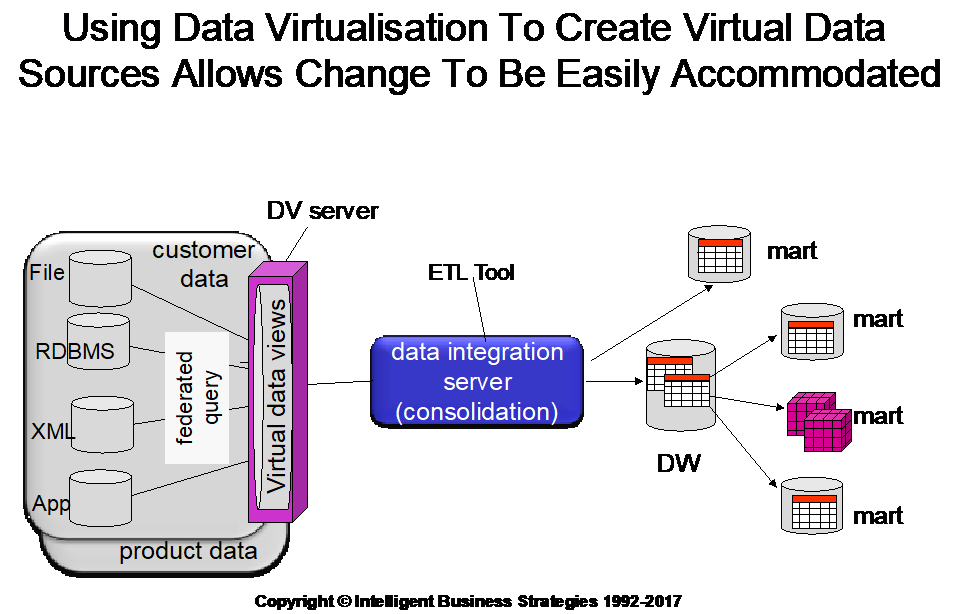
One of the biggest problems in an M&A is how to merge data warehouses when the source OLTP systems are also merging! In this kind of situation, it is often the case that structural changes are being made to the OLTP systems that are also data sources to your data warehouse(s). The problem here is that frequent changes to OLTP systems will cause ETL jobs to ‘break’ and so constantly force maintenance to ETL jobs that extract data from OLTP systems before cleaning, transforming and integrating that data to populate a data warehouse. As one manager put it ‘It’s like standing on quicksand”. A good way to stop this continuous ‘breakage’ of ETL jobs is to introduce virtual data sources between source OLTP systems and your data warehouse using data virtualisation technology like the Denodo Platform. This results in data warehouse ETL jobs extracting from virtual tables rather than physical ones. Such a move allows you to decouple the physical source systems from ETL jobs so that if physical OLTP system sources have to change in structure to accommodate a merger, you just need to alter the mappings between the physical sources and the virtual sources thereby shielding data warehouse ETL jobs from being impacted.
The same can be done between data warehouses and data marts when these systems are merging although I would recommend also switching to virtual data marts in that case. It sounds simple but I would prefer it described as practical and effective because it allows both operational and analytical teams to work to get an M&A done while shielding one from changes caused by the other
Stabilising Data Warehouse ETL Processing
Virtual data sources can also be used to stabilise ETL processing for data warehouses. In this case however we are doing it as a design choice. Again it will shield ETL jobs from structural changes in data sources (which is always a good thing) but what it also allows us to do is build target oriented dimension and fact based ETL jobs such as the customer ETL job, the product ETL job, the orders ETL job etc with corresponding dimension and fact based virtual data sources. It means that we highlight only the data needed in underlying physical sources for a specific dimension or transaction type based ETL job via the virtual source and then extract from there. We are not necessarily trying to join everything in the data virtualisation server but we can at least ‘ring fence’ the data needed. Also it keeps the design focused on the target rather than building ETL jobs for every source table for example:
Simplifying Self-Service Data Preparation
This last use case is a way of using virtual data sources to make it easier for business users with self-service data preparation or data integration (DI) tools to access data across multiple data sources in order to help make them more productive, while also enforcing security to prevent unauthorised access to sensitive data and reducing the need to copy data. It is a way of using data virtualisation to encourage reuse and while enabling governance to be introduced into a self-service data integration environment.

Other use cases exist for virtual data sources – just a few are covered here. For me it is the ability to de-couple physical data sources from ETL processing, improve design and introduce governance that really make virtual data sources useful in practice.
- Enabling a Customer Data Platform Using Data Virtualization - August 26, 2021
- Window Shopping for “Business Ready” Data in an Enterprise Data Marketplace - June 6, 2019
- Using Data Virtualisation to Simplify Data Warehouse Migration to the Cloud - November 15, 2018