
Recently there has been a lot of discussion around the concept of the logical data warehouse. What is the cause of this buzz? Why are logical data warehouses so important for data professionals? To understand this, we first need to look at the role of a logical data warehouse i.e. what is it and what does it do?
A logical data warehouse is a modern data architecture which allows organizations to leverage all of their data irrespective of where the data is stored, what format it stored in, and what technologies or protocols are used to store and access the data. The logical data warehouse infrastructure provides an abstraction and integration layer that hides these details from users of the data. This allows the users to seamlessly and easily access data in traditional relational databases and data warehouses, big data in Hadoop or NoSQL databases, files-based data, data in the Cloud or from SaaS applications such as Salesforce, and so on. If you want to know more about the logical data warehouse, you can find more detailed descriptions and use cases in other blog posts, such as here, here, and here.
So, why is the logical data warehouse so important and why should you care?
To understand this, you have to look at data – and data storage and processing – has changed over the past few years and how those changes affect your data architecture. Obviously I talking about the big data explosion and the surge of interest in advanced analytics platforms for dealing with this big data, such as Hadoop, Spark, and so on. The following infographic (courtesy of Teradata) illustrates some of these changes…and challenges.
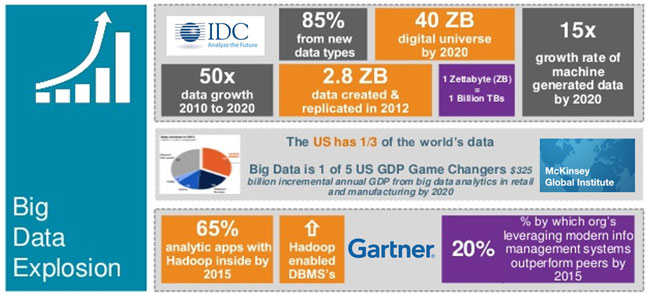
As data volumes grow (by 50x according to IDC), the data that is ‘new data’ will be 85% of all data. That is, it will be unstructured or multi-structured data that doesn’t nicely fit into you existing databases or data warehouse. Not that you’d want to put all of this data in these anyway! This means that your data architecture of the future will contain many data stores containing different types and formats of data – you’ll have relational databases, data warehouses (these are not going to simply disappear just because you have a big data project), Hadoop clusters – using multiple data processing and analytics tools such as Spark, Mahout, and R – file-based data, and even data that is external to your organization. With all of these data stores, it very easy to create more and more data silos and not getting the full value out of all of your data. (In fact, most initial big data projects result in big data silos because integration and management are afterthoughts to the project team).
Of course, the optimists will always say that a data lake is the solution to all of these problems…well, optimists and the Hadoop vendors. Errmm…no! The concept of a data lake is great, but I really question how many organizations will ever get to a single data lake repository. Just the way that we use data – processing and refining and aggregating the data to get to actionable insights or trends – means that we will always have multiple data repositories each with different qualities and veracity of data until we get to the ‘authoritative’ data store for regulatory and statutory reporting. So the question still remains; how do you avoid creating data silos with the multiple data stores?
This is where the logical data warehouse comes in to play. The logical data warehouse allows you to access and govern all of these different data stores as if they were a single logical (or virtual) data store. Through the logical data warehouse, all the differences and complexities of these different data stores are hidden – abstracted away – and the data can be combined and transformed (on demand) to provide a common and consistent view of all of your data which allows you to make full use and get full value from your data assets. In fact, Denodo’s data virtualization reference architecture for analytical and big data scenarios (below) illustrates how data virtualization provides this critical semantic and abstraction layer allowing data consumers to access the data as if it comes from a single, integrated source.
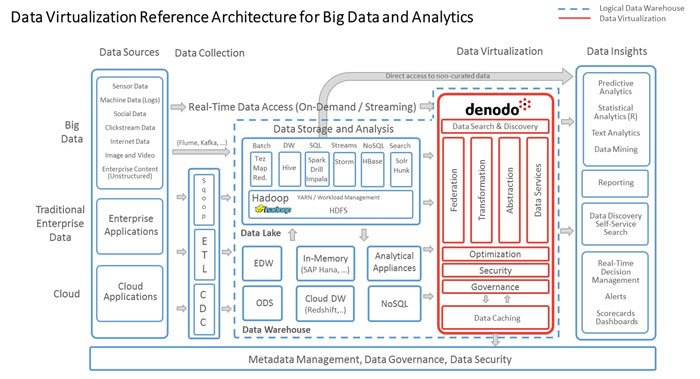
As explained in some of the other blog posts that were referenced earlier, data virtualization is a key technology for implementing a logical data warehouse architecture – it’s not the only technology in the architecture…but it is critical for successfully implementing a logical data warehouse. And, given the importance of a logical data warehouse in managing your future information needs, this makes data virtualization pretty special and something that you should look at closely.

- The Energy Utilities Series: Challenge 3 – Digitalization (Post 4 of 6) - December 1, 2023
- How Denodo Tackled its own Data Challenges with a Data Marketplace - August 31, 2023
- The Energy Utilities Series: Challenge 2 – Electrification (Post 3 of 6) - July 12, 2023