
Intelligent caching is a key capability of an enterprise class data virtualization platform. Caching serves many purposes: one of the common uses is to enhance performance when dealing with sources with varying latencies, an increasingly common situation with data virtualization being used more frequently as the data fabric knitting together disparate systems in different physical locations.
Imagine a scenario involving combining data from a cloud hosted Software as a Service (SaaS) application e.g. Salesforce in conjunction with data from an on-premise database.
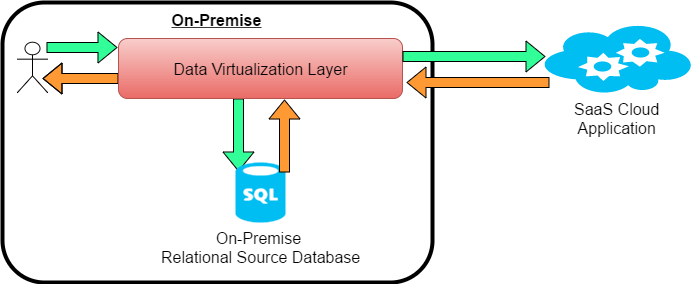
The SaaS application and on premise database return data to the virtualization platform at different speeds, with the data returning from the SaaS system often becoming the bottleneck for the overall query performance – it being accessed over a WAN over which we have little control of the intermediate network. In this situation, caching the data from the SaaS application will usually result in better overall query performance.
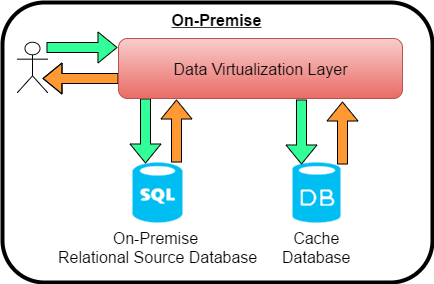
Caching the data seems to come at a cost! When this data is accessed through the data virtualization platform it can potentially be out of date with the source system it was derived from, introducing a degree of latency which the consuming application needs awareness of in order to meet any SLA. Updating the cache more frequently is often suggested as a solution in an attempt to balance the competing concerns of performance and data-freshness needs of the client application. However, replicating data in the caching system and doing it more often seems to be contradictory to the principles of data virtualization which promises real time federated access to data. Is it possible to get reasonable performance and real-time access to your data?
The solution lies in the incremental query caching capability of the data virtualization platform. With minimal configuration, it is possible to merge the data coming from the cache with only the changed or newly added data from the remote system at query time.
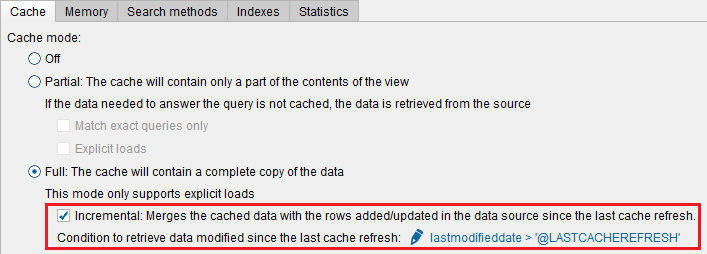
Typically, a daily scheduled job is configured to fully load the cache with a complete data set from the SaaS source. Subsequent to this, whenever a query is sent from the client application, the data virtualization server will send two queries out:
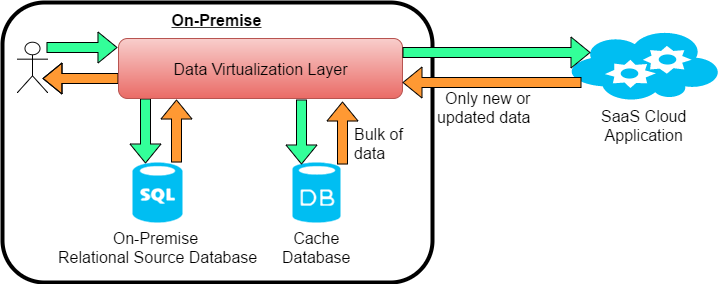
1) A first query to the cache store to retrieve the bulk of the data.
2) A second parallel query to the remote system requesting any data that has changed or was newly added since the last time the cache was fully loaded.
These two data sets are transparently merged and sent back to the client application. Since only a small amount of data is coming back from slower remote system and the majority of data from the closer proximity cache, the overall performance of the query is improved. This performance benefit is realized because network traffic is intelligently reduced at query time.
With a modern data virtualization platform, there is no need to sacrifice performance over real-time access to your data, you can indeed have your cake and eat it!
To learn more about data virtualization intelligent caching, watch our sessions from Fast Data Strategy Virtual Summit now on-demand. SimplicityBI is proud to be a sponsor of this summit which was an informative event packed with analyst insights, real implementation stories, and practical advice.
This blog was penned by Arif Rajwani, Data Architect and Co-Founder of SimplicityBI.