
Many organizations today have either already created or are in the process of creating a data lake. There are of course multiple configurations of a data lake including:
- A centralized data lake typically on a single data store such as Hadoop or cloud storage like Amazon S3
- Multiple stand-alone data lakes
- A logical data lake where the data in the lake is distributed across multiple data stores but is managed as if it is centralised
From the global data lake survey (Figure 1) I have been conducting, it is clear that the logical data lake is the configuration that dominates.
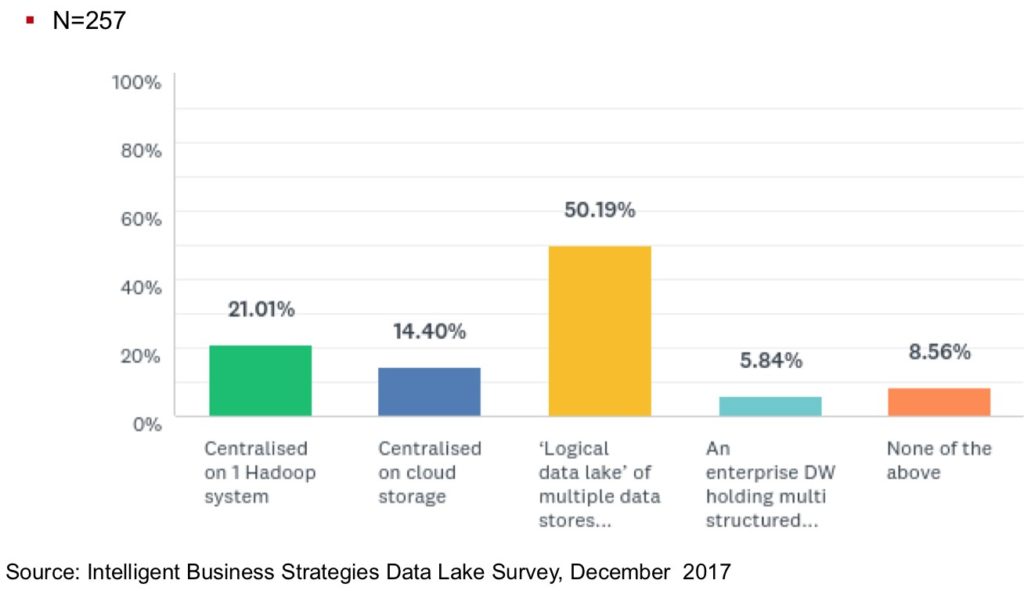
Fig. 1
The logical data lake consists of multiple data stores including data warehouses, master data management, cloud storage, NoSQL databases and Hadoop systems. However, it is managed as if it is a single system and so we have the flexibility to ingest, prepare, analyze and provision data in any or all platforms. To cater for this degree of flexibility, data management software has to rise above the multiple data stores in the data lake and be able to connect to all of them in order to allow data to be ingested into one or more data stores, prepared, integrated and analyzed.
Data virtualization plays an important role in simplifying access to the trusted data and insights produced in this environment. This is shown in Fig. 2.
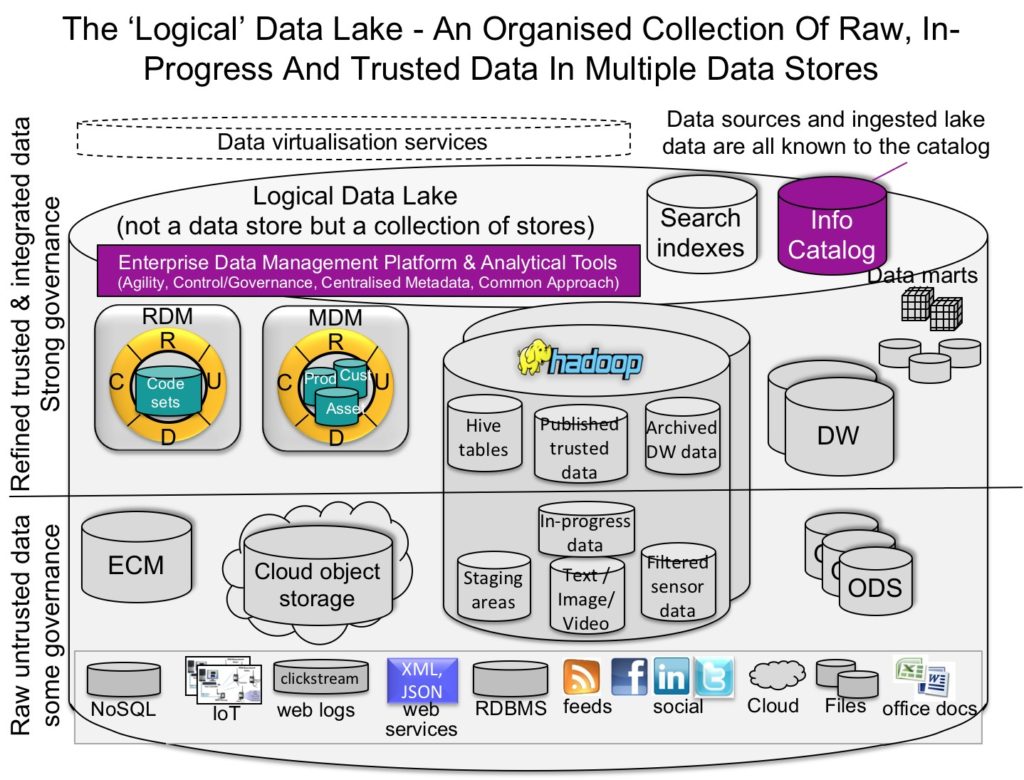
Fig. 2
However even if your data lake is a single centralized data store and not a logical data lake, it is the combination of the information catalog together with data virtualization that is important.
The role of the data catalog is to discover, profile, tag and classify data and also to map it to a business glossary so that people know what the data means. It also provides lineage and helps organize data in the data lake making it easy to find. Increasingly the information catalog is being plugged into data preparation tools, data science workbenches and self-service BI tools so that people working in data and analytics projects can easily see across the logical data lake to find the data they need.
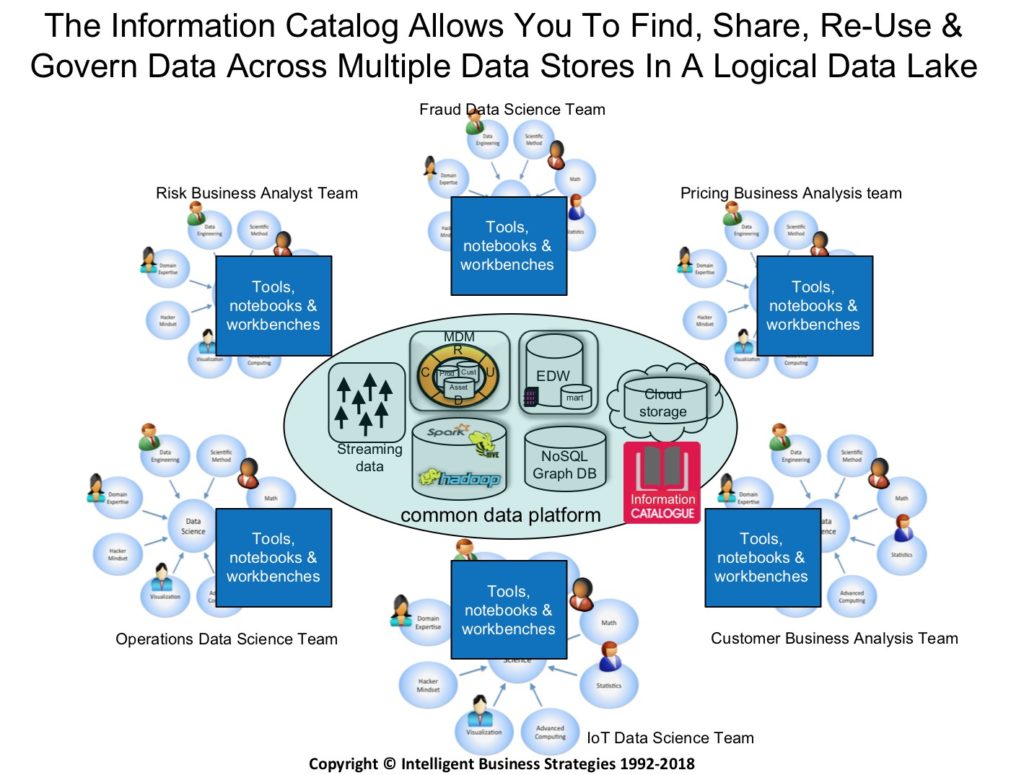
Fig. 3
The question is, how does the information catalog work with data virtualization to improve agility when provisioning data in a data lake?
There at least are two ways to make use data virtualization with the catalog:
- The first way is to be able to browse the catalog and find the data you need. The catalog can then be used to launch data virtualization to allow you to preview that data from within the catalog. This allows data virtualization to fulfill the role of a virtual data connector and requires the data virtualization server to support automatic schema discovery (schema on read).
- The second way is once you have found the data you need, then data virtualization can be used to provision it, giving you a virtual view over the logical data lake so that you can easily access the data you need even if it is in multiple data stores within the data lake. This means that there is no need to copy data in the data lake somewhere else. It provisions it via virtual views so that the data remains governed and managed in the data lake. Multiple virtual views can then be published to the catalog to quickly provision data on demand. So this is a powerful combination virtual views of trusted data available in the catalog to quickly provision data. This is shown in Figure 4.
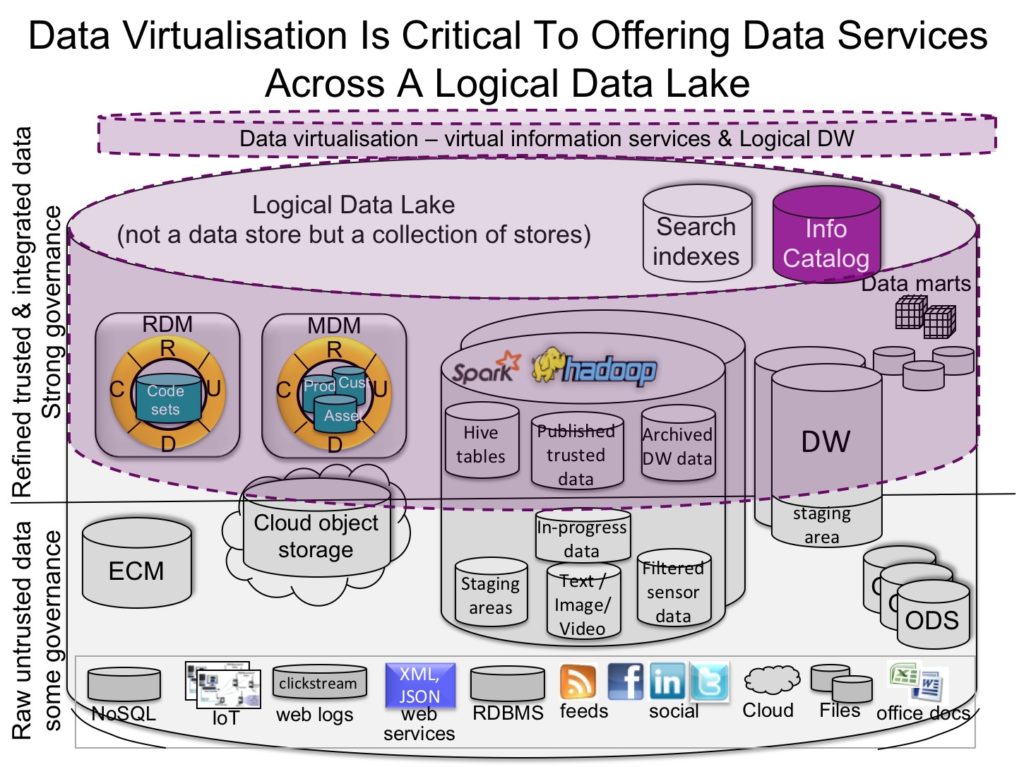
Fig. 4
For more information on the data catalog and the capabilities of data virtualization, please take a look at the following resources:
- Fast Data Strategy Virtual Summit 2018: Leap to Next Generation Data Management with Denodo 7.0
- Data Management Reimagined Panel
- Data Virtualization or SQL-on-Hadoop for Logical Data Architectures
- Denodo Platform 7.0: Bridging the Gap Between IT and Business Users
- Enabling a Customer Data Platform Using Data Virtualization - August 26, 2021
- Window Shopping for “Business Ready” Data in an Enterprise Data Marketplace - June 6, 2019
- Using Data Virtualisation to Simplify Data Warehouse Migration to the Cloud - November 15, 2018