
In recent years, there has been a growing interest in data architecture. One of the key considerations is how best to handle data, and this is where data mesh and data fabric come into play. But what are the key differences between data mesh and data fabric?
Data mesh is a cultural and organizational shift in how organizations manage their data. A data mesh takes a decentralized approach to data architecture, in which data is organized by specific business domains, such as marketing, sales, and customer service. This approach enables teams to take ownership over their data and make decisions about how to best manage it to optimize business outcomes and value.
On the other hand, data fabric is an architectural and technological approach to data management focused on integrating data across disparate data sources or hybrid, multi-cloud ecosystems. Additionally, data fabric automates data engineering tasks to reduce complexity. Data fabric uses active metadata, semantic data models, data catalogs, and artificial intelligence/machine learning (AI/ML) to empower everyone to find, access, and integrate data, and share it securely.
Should I Use a Data Fabric or a Data Mesh?
This is a common question, but it is not a question of choosing between one or the other. It is probably more appropriate to ask whether one or both might be appropriate, depending on the need.
When it comes to choosing a data fabric and/or a data mesh, it’s important to understand the trade-offs and benefits of each. A data fabric is a flexible, reusable, and powerful data management approach that is critical for any organization that struggles with distributed data silos.
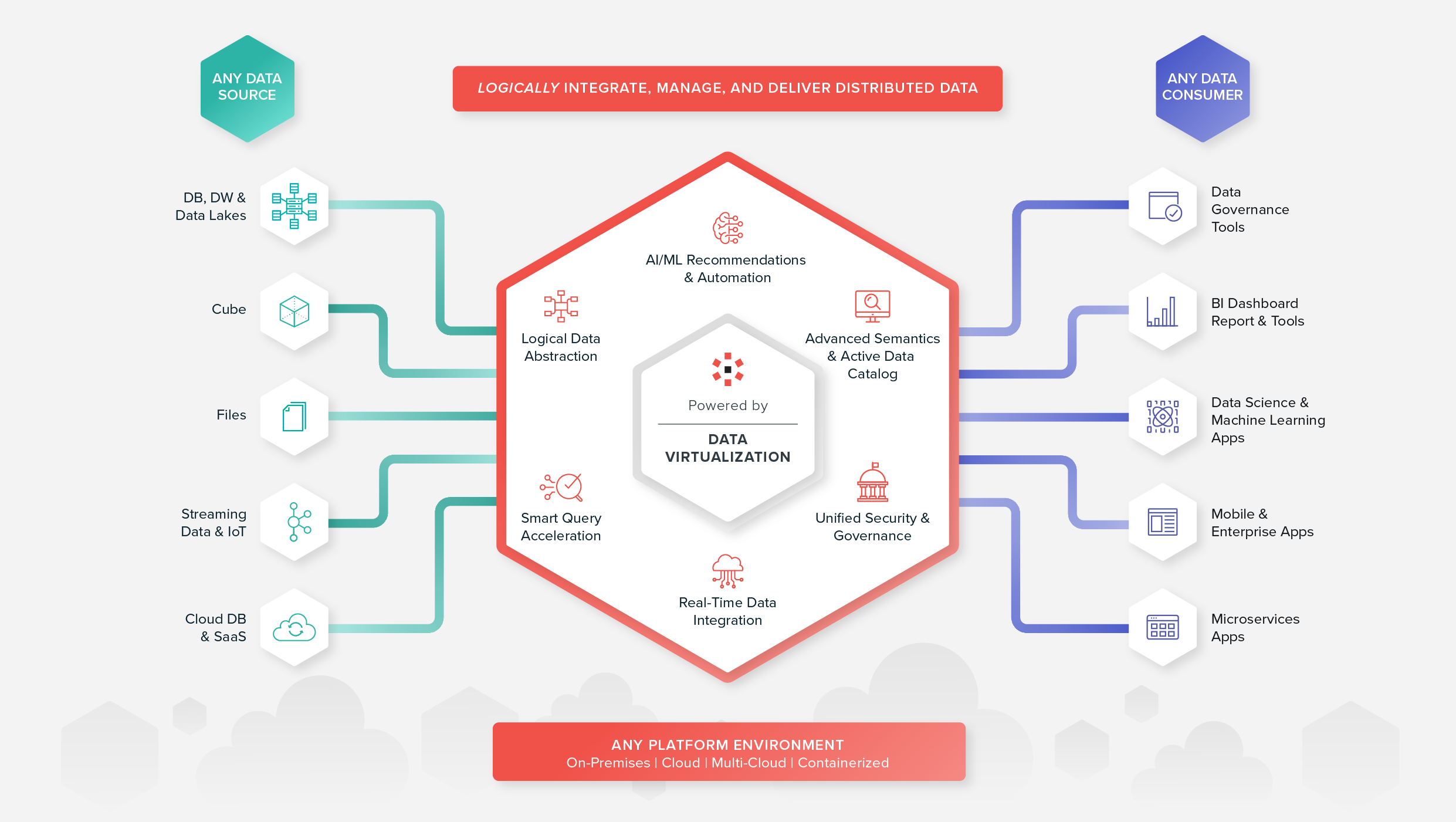
On the other hand, a data mesh may not be ideal for all organizations. For companies that are centrally structured, a federated, localized data management approach may not be needed. For organizations that have very large complex data ecosystems such as banks, which have often been built organizationally around the products that they offer to customers, a data mesh might be ideal. For those who do embark on a data mesh strategy, using a data fabric as a technology foundation could be the difference between success and failure. A data fabric will make it easier for the domain teams to access and define their data products. It would enable them to share those data products, and most importantly, it would provide the IT team with a centralized way to ensure that proper security and controls were in place to protect data assets.
How Can I learn More?
Here is a list of resources for better understanding the differences between data mesh and data fabric:
[Webinar] Logical Data Fabric vs Data Mesh. Does it Matter?
[Podcast] Data Mesh, Why Should I Care?
[Analyst Report] The Value of Data Virtualization in a Data Mesh
[Blog] Why Data Mesh Needs Data Virtualization
[Webinar] Design Guidelines for Data Mesh and Decentralized Data Organizations

- Top 7 Business Best Practices for Data Projects - January 11, 2024
- Data Management Trends in 2023: My Top 5 Trends to Watch - January 25, 2023
- Data Mesh vs Data Fabric: Understanding the Key Differences (2023) - January 17, 2023
Hey,
I just stumbled upon on your website and this article about Data Mesh vs Data Fabric benefits of wearing amethyst you have done an amazing job and belief me that’s so helpful.