
In my previous post, I described the data fabric architectural pattern. Before turning to the data lakehouse, let’s first look at what I mean by an architectural pattern.
The Power of a Pattern
An architectural pattern, or logical architecture, describes a system’s major functional components—data/information, process, or both—in a generic, simplified way, often focused on some set of business and/or environmental characteristics that are its key drivers. It avoids specific products, attempting to be as vendor neutral as possible. The figure below shows typical architectural patterns for a basic hub-and-spoke data warehouse and a data lake. As well as allowing a brief discussion of the principles of architectural patterns, it offers a perfect starting point for describing the data lakehouse, which—as the name implies—attempts to combine the two worlds.
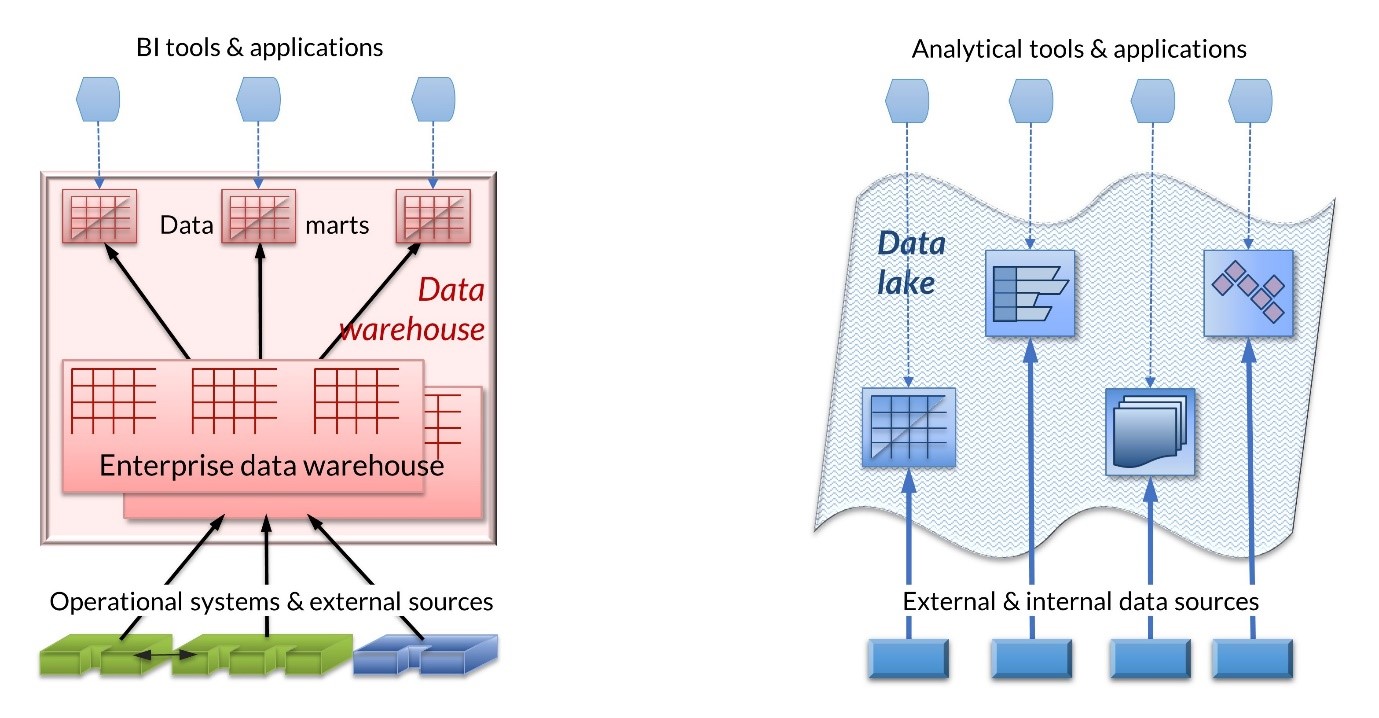
Different arrow and widget designs represent different types of function and storage. The different types of data stores—relational, flat file, graph, key-value, and so on—have different symbols, and it is clear that a data lake contains many different storage types, while the data warehouse is fully relational. The heavy black arrows show bulk data transfer between data stores, whereas the light blue dashed arrows show access to data stores from applications. The black arrows into and out of the enterprise data warehouse (EDW) denote strong transformation function (schema on write) and are arranged in funnel patterns to imply consolidation of data in the EDW. These functions are largely IT controlled. The solid blue feeds to the data lake denote minimum levels of transformation of the incoming data and are operated independently, often by data scientists or business departments. Data in a lake is therefore often inconsistent—the so-called data swamp—and it is up to the users to manage its meaning (schema on read) and—a more difficult proposition—quality.
Introducing the Data Lakehouse
The data lakehouse concept was introduced early in 2020 by Databricks, a company founded in 2013 by the original creators of Apache Spark™, Delta Lake and MLflow. According to Databricks, the data lakehouse is a platform that “combines the best elements of data lakes and data warehouses—delivering data management and performance typically found in data warehouses with the low-cost, flexible object stores offered by data lakes.” It builds on a data lake foundation because, according to the authors of a recent lakehouse Q&A, they often contain more than 90% of the data in the enterprise. The lakehouse therefore attempts to eliminate or, at least, greatly reduce the common approach of copying subsets of that data to a separate data warehouse environment to support traditional BI that data lake tools struggle to do.
According to the original paper defining the architecture, a lakehouse has the following features:
- ACID transactions for concurrent data read and write supporting continuous update
- Enforcement, evolution, and governance for schemata such as star and snowflake
- Support for using BI tools directly on the source data, reducing staleness and latency, and eliminating the copies of data found in a combined data lake and warehouse solution
- End-to-end streaming to serve real-time data applications
- Open and standardized storage formats, such as Parquet, with a standard API supporting a variety of tools and engines, including machine learning
- Storage decoupled from compute, for scaling to more concurrent users and larger data sizes
- Support for diverse workloads, including data science, AI, SQL, and analytics
- Support for diverse data types ranging from structured to “unstructured” data
The first four points are directly related to the goal of supporting modern data warehousing from a data lake base, while the remainder relate more to “big data” applications.
As is often the case with vendor-defined architectures, no architectural pattern is offered for the lakehouse. Rather, a product or set of products is suggested as implementing the concept. In this case, the complementary/competing open-source products/projects mentioned are: Delta Lake (an open-source storage layer supporting ACID transactions), Apache Hudi (a platform for streaming data with incremental data pipelines), and Apache Iceberg (an open table format for very large analytic datasets). Apache Spark provides an underlying platform.
Data Lakehouse — Questions Arising
Although building on top of the data lake, the features described and the products mentioned focus heavily on the ingestion, management, and use of highly structured data, as is the case with a data warehouse. In this respect, the data lakehouse appears to build a data warehouse on a different platform than traditional relational databases, while enabling AI and analytic tools to use the same underlying data. The extension of good data management and manipulation practices beyond relational data to structures such as Parquet, ORC (Optimized Row Columnar), and even CSV files is welcome and valuable in reducing the prevalence of data swamps. Although traditional relational databases would seem to fit neatly, they are largely excluded from consideration, because of concerns about “vendor lock-in” typical of open-source vendors.
ACID transaction support is strongly emphasized. This is driven by the growing need to support streaming inputs from clickstreams and the Internet of Things, as well as the need to offer version management for more file-based ingestion. The business focus is thus very much slanted toward analysis of data from external Internet-sourced data, in large volumes and at high velocity. Similar technology considerations pervade traditional data warehouse thinking, although the focus there is often more on data from operational systems.
The lakehouse description provides little evidence of how the governance and version management of more loosely structured data/information—such as text, audio, image, and video—is to be achieved. This omission is concerning, given the volumes of such data/information and its importance in AI.
Perhaps most concerning of all is the underpinning notion that all the data a business needs can be housed in the same (lake-based) platform and processed by a single set of tools. Of course, the notion speaks to the desire for good governance and security, reduced data management, and lower storage costs. However, experience has proven that data monoliths have their own serious drawbacks: inability to meet all business needs equally, complex and lengthy implementation, and ongoing inflexibility to change. Based on prior knowledge of data warehouses and data lakes, it seems likely that the lakehouse will also need to adapt to be part of a logical, distributed approach, just one of a variety of data stores accessed via data virtualization technology.
Conclusion
The data lakehouse is very clearly a pattern coming from teams experienced in open-source / extended Hadoop / cloud-centric data storage and delivery systems. This focus may be appropriate for enterprises with more distributed environments, where the data center of gravity leans heavily toward cloud. Enterprises with more on-premises, traditional environments—even if aiming toward significant cloud migration—would be advised to dig more deeply into the details of the lakehouse approach to understand its limitations. A clear and sufficiently detailed architectural pattern from the designers of the data lakehouse would be of substantial benefit.
In the next and final post of the series, I’ll be looking at data mesh, an architectural pattern that starts from an uncommon point of view.

- The Data Warehouse is Dead, Long Live the Data Warehouse, Part II - November 24, 2022
- The Data Warehouse is Dead, Long Live the Data Warehouse, Part I - October 18, 2022
- Weaving Architectural Patterns III – Data Mesh - December 16, 2021
Hello Barry! Thanks for the helpful article. I also recommend another one: https://skyvia.com/blog/what-is-data-integration, which considers data lake integration patterns.