
Just like any other software project, a data virtualization project is likely to face challenges related to changes of control. A key tool to address this challenge is by implementing a Version Control System (VCS).
The key functionalities of a Version Control System are:
- The ability to compare changes over time
- The ability to revert metadata to its previous state
- The ability to determine who made certain changes that might be causing a problem
- The ability to see who added a specific data source or view
It is a common misconception to minimize the importance of these functionalities in the initial stages of your data virtualization project but, as argued in this post, environments composed of multiple teams and enterprise departments can quickly become unmanageable if you do not use a VCS. These minor capabilities can be the difference between a successful or an unsuccessful project.
Concurrent vs blocking systems
Version control systems can be classified in two types, according to how they manage concurrent modifications of the same element by different developers:
- A ‘blocking’ system, refers to the function that elements are blocked while a developer is making changes. It is only until these changes have been “checked in” that another developer can step in and make their own modifications.
- In a ‘concurrent’ system, each developer has their own copy of the element on which they made changes to their heart’s content. This means that developers can work simultaneously on the same element without effecting each other’s work. The VCS system takes care of merging the changes of the different developers, except when those changes are conflicting. In cases such as this, the last developer to check in the conflicting changes will be sent a warning and can resolve the conflict.
So, which system is more advantageous when using data virtualization? Despite a number of data virtualization vendors adopting the ‘blocking’ within their technology, I would argue that this system can be seriously detrimental to the productivity of your team. In many cases, developers can be blocked from making progress on particular elements because they have to wait for previous changes to be ‘checked in’ – this can take days or weeks in some cases. A nightmare!
By definition, the concurrent approach grants each developer his own development space to work alongside his colleagues.
For a more productive data virtualization project, I would recommend using a technology which implements the concurrent approach.
Concurrent approaches: two possible scenarios
When deploying a version control system environment, there are two possible scenarios to bear in mind: one server per developer, or one database per developer. You will need to choose which data virtualization platform fits better for your developers because this will have a direct effect on the productivity of your team.
One data virtualization server per developer
In this scenario, each developer uses their own data virtualization server and creates a virtual database for every project they are working on. The version control repository will store the consolidated metadata of every database.
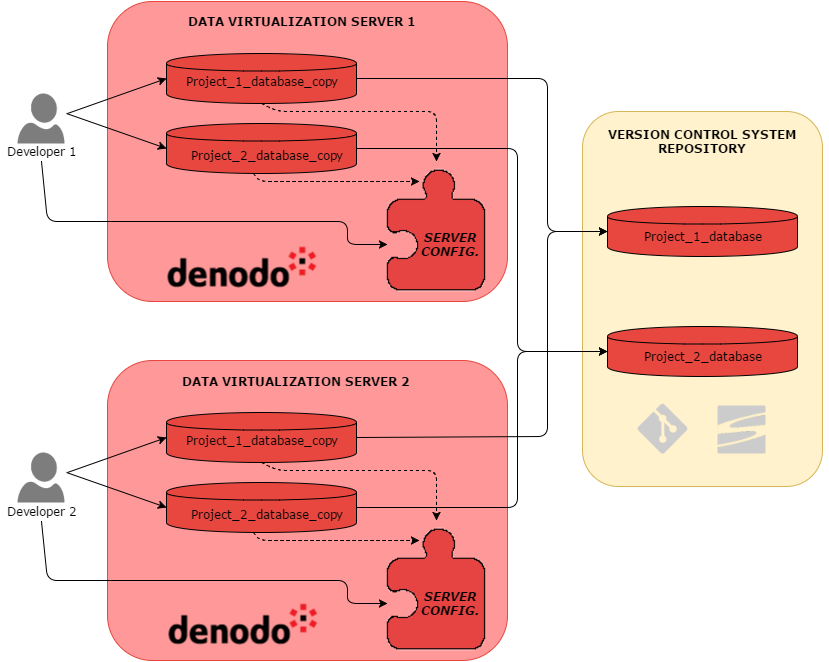
So, before starting to develop a new feature for a specific project, the user must synchronize their virtual database with the metadata stored in the repository. Then, the user can implement the changes related to the feature and commit them into the repository. Once the virtual databases are synchronized everyone can see the new changes.
The developer can perform the following tasks without interfering with other users:
- Restarting the server
- Configuring server behavior (view optimizations, i18n, cache, etc.).
- Managing users and roles privileges for the created views.
- Managing custom functions or types used in several virtual databases.
- Configuring the version control system.
One database per developer
In the second approach, only one data virtualization server is used and each user has a copy of a virtual database for every project that is being developed.
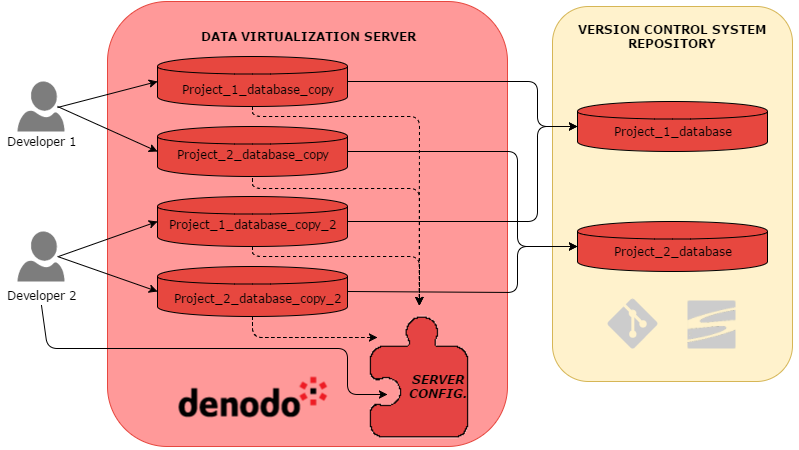
The development process is the same as described above, but in this case you will notice that the data virtualization platform is storing several copies of the same database, all created by separate developers. This is a good way to avoid performing the same modifications in the same database as your team members.
Just like in the previous scenario, there are certain conflicts that you will have to deal with in the synchronization process. Additionally, it is worth noting in this example that there will be someone in charge of administration tasks of the data virtualization server (i.e. server configuration, user permissions etc.) which will allow other members of the team autonomy to work on their own tasks.
Conclusions
Concurrent Version Control Systems behave in a far more advanced way than ‘blocking’ systems which actually hinder the progress of your data virtualization project. It is a wise choice therefore to seek out a data virtualization vendor which incorporates the concurrent system within their technology.
Depending on the requirements of your project, you have two options: one data virtualization server per developer or one database per database. The main difference between these two “working architectures” comes down to the responsibility of the administration tasks in the data virtualization servers.
The first approach (one data virtualization server per developer) allows developers to perform any development or configuration change without interfering with anyone else. The downfall of this method is that it complicates certain administrative tasks i.e. the installation of platform updates or the enforcement of certain configuration policies in the development environment.
The second approach, in turn, allows for centralized management of administrative tasks but it is more restrictive for developers.
So ultimately, it is important to bear these challenges in mind when choosing your data virtualization vendor for your next project.
References:
https://git-scm.com/book/en/v2/Getting-Started-About-Version-Control
https://en.wikipedia.org/wiki/Version_control