
Update: Interested in data virtualization performance? Check out our most recent blog posts, “Performance of Data Virtualization in Logical Data Warehouse Scenarios” and “Physical vs Logical Data Warehouse Performance: The Numbers.”
The topic I probably get asked most about is Data Virtualization performance. I would like to address several common misconceptions on this subject.
Many of the remarks I often hear can be summarized in the following (false) statements:
- “In data intensive scenarios, Data Virtualization requires moving big amounts of data through the network”.
- “Moving data through the network is slow”.
- The (again false) corollary is that “Data Virtualization queries are slow in data-intensive scenarios” such as those involving Big Data.
Before we jump into details, here is a video which can provide you with a good overview about the topic:
The reality is that data-intensive scenarios require processing large amounts of data, but not necessarily transferring them. Actually, query execution can usually be organized in such a way that you only need to transfer the results of the data analysis from each involved data source. And, almost by definition, these results should be a short summary of the analyzed data, and much lower in size. Let me illustrate this idea with an example.
Let’s say you work for a big retailer which sells around ten thousand products. You have a Data Warehouse with sales information from the last year, stored in a facts table with, say, 200 million rows. Let’s also assume you periodically offload sales data corresponding to previous years to a Hadoop-based repository running Hive (or a similar system), and that you currently have information about one billion sales stored there.
Now let’s suppose you want to run a report to obtain the total amount of sales of each product in the last two years. This requires integrating product data with sales information from both the Data Warehouse and the Hadoop-based system. Notice the size of the final report is only ten thousand rows (one row for each product).
Common (and false) “wisdom” about Data Virtualization performance assumes that this report would be executed using the naive query plan illustrated in Figure 1: the Data Virtualization tool pushes down to the data sources the filtering conditions (sales in the last two years), retrieves all the rows verifying those conditions and then computes the report entirely by itself. Although pushing-down the filter conditions allows retrieval of “only” 150 million rows instead of the total of one billion rows from Hadoop, the overall plan still requires transferring roughly 350 million rows, so execution will probably be painfully slow.
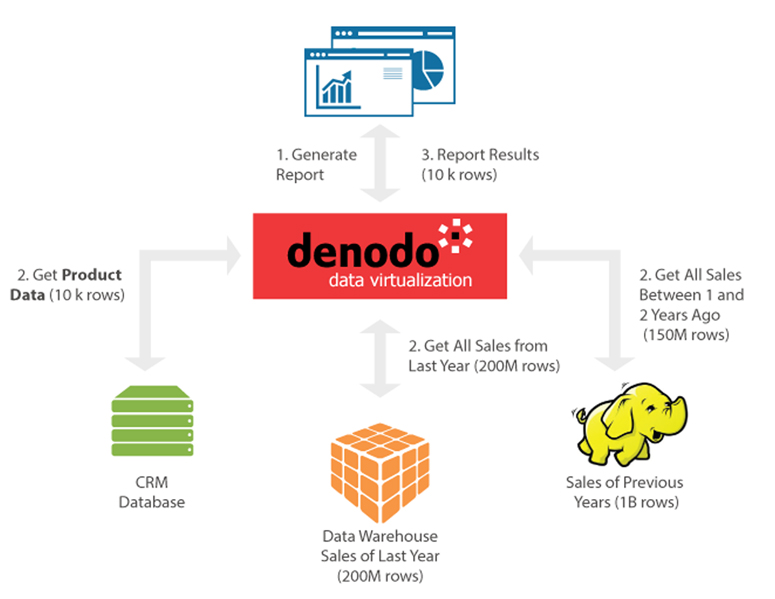
Data Virtualization Performance – Figure 1
Actually, it is true that many Data Virtualization tools will generate a naive execution plan like this! Nevertheless, a first-class Data Virtualization tool can do much better. Figure 2 illustrates the query plan Denodo would automatically generate to create the aforementioned report. Each data source computes the total amount of sales by product on its own data, and transfers the partial results to Denodo. Denodo then computes the final result for each product by adding the partial sales amount computed by each data source.
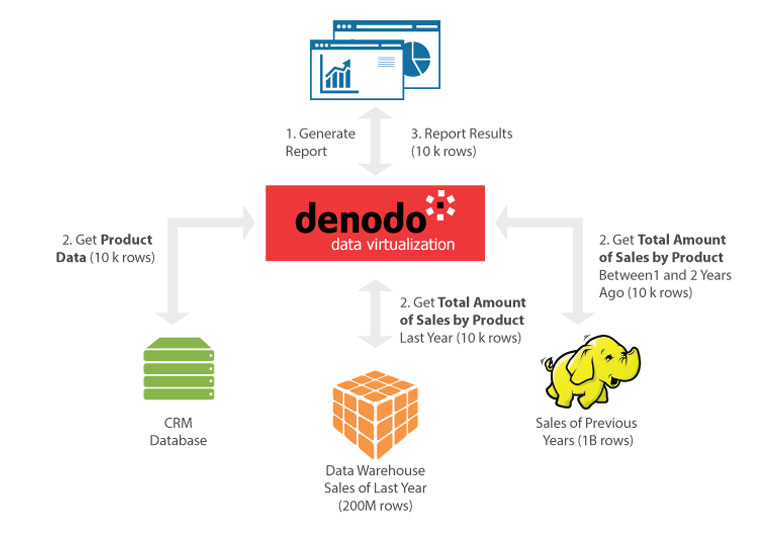
Data Virtualization Performance – Figure 2
As you can see, we have gone from moving 350 million rows to roughly 20 thousand; only twice the size of the report results. This volume of records can be sent through modern Gigabit local networks in a matter of seconds. (By the way, it is worth checking this table, originally compiled by Jeff Dean of Jeff-Dean Facts fame, to remind us how fast networks have become in recent years, up to the point of surpassing disk read times in many cases).
Intelligent query rewritings like the one shown in this example are only one among many optimization techniques available in Denodo that can be used for virtualizing data-intensive scenarios, and which go far beyond the conventional query optimization techniques used in databases and less sophisticated Data Virtualization systems. Other examples are:
- Automatic Data Movement, which automatically transfers small amounts of data from one data source to a temporal table in another data source, to maximize query push-down to the target data source and minimize overall network traffic.
- Incremental Queries, which retrieve from the data source only the data changed since the last time the data was refreshed.
- … and many more!
Also recommended: Performance of Data Virtualization in Logical Data Warehouse Scenarios

- Performance in Logical Architectures and Data Virtualization with the Denodo Platform and Presto MPP - September 28, 2023
- Beware of “Straw Man” Stories: Clearing up Misconceptions about Data Virtualization - November 11, 2021
- Why Data Mesh Needs Data Virtualization - August 19, 2021
Interesting and informative article.
Surely in most organisations, product information would also be available in the Data Warehouse, therefore avoiding the need to go to the CRM system?
Or is it that since you are using virtualisation, you don’t need to store product data in the warehouse?
Hi Abdul,
Thank you for your comment. If the customer information is in the DW, Denodo would obtain it from there without needing to go to the CRM system. In that case, we would only need to integrate two data sources instead of three.
Notice however that even though at least basic customer information is usually in the DW, in some cases you may still want to obtain it from the CRM. For instance, some reports may require customer data updated in real-time. Other reports may require access to ‘extended’ fields that re not currently replicated in the DW. In our experience, this is specially common when you are using a SaaS CRM as Salesforce.
Hope this helps,
Thanks for an informative post and a good summary of workload re-distribution through the query re-write. It explains really well how a good integration tool such as Denodo avoids becoming a bottleneck.
Now pushing the work back into the source system revives a different but a very related question of whether the Data Virtualization obviates the need for Data Warehouse (DWH) — a narrative sometimes espoused by the providers of Data Vrtualization. One might argue that the two defining features of the Data Warehouse compared with OLTP (CRM/ERP/etc.) systems are (1) historization (older data often required for analytics) and (2) relieving the OLTP from the burden of analytical queries (long reads, as opposed to OLTP-characteristic short writes), and optimizing DWH data structures and queries for those analytical long reads.
It looks like in your example with 3 source systems (CRM/DWH/Hadoop), CRM will be again subjected to the long reads, and thus CRM’s performance may suffer in those moments. Is that an issues concern? How is it dealt with?
Hi Sergey,
Thanks for your comment ! I think your comment touches two interesting topics.
First, will DV remove the need for Data Warehouses ? In general, the answer is ‘no’. There may be some cases where DV can directly access the operational data sources to compute the required reports, and in these cases (and as explained below), you can also use caching to decrease the impact in the underlying systems. But in most complex analytics architectures, you will still have good reasons (such as the ones you mention) to include Data Warehouses. Nevertheless, DV drastically reduces the need to create physical data marts (they can be replaced by virtual data marts) and allows to very easily include in the reports data that is not in the DW. It is also a great solution to integrate several DWS/Data Lakes.
Second, how to protect the CRM from expensive queries?. Well, the first thing to notice is that in this example the most expensive parts of the query (the aggregations on the large sales tables) are executed by the DW and the Data Lake, while the CRM only needs to answer a relatively “cheap” query (the list of customer names and ids). That would probably hold true in most other analytics queries on this scenario because the CRM only contain dimension data, and typically the expensive aggregates are computed in the fact tables.
Anyway, if the workload in the CRM was a problem, there are several alternatives you could consider: 1) Restrict the type and/or number of queries that can be sent to the CRM. Denodo allows easily configuring this. 2) Cache the CRM data. Denodo provides several caching options (partial, full, incremental,…), so queries do not need to hit the CRM and can access a local copy instead. 3) You could also replicate the customer data in the DW or the Data Lake. In that case, Denodo would integrate data from two data sources (the DW and the Data Lake), instead of three
Hope this is useful !
Your example is bad. The performance problem with data virtualization is come when you have to cross join all sources of data and delivery the final result… not when you launch queries separately !!!
Hi Killy,
Thanks for your comment. This example actually needs to join all sources of data. Data from all Products in the CRM data source is cross joined with the all the Sales data from the last two years in DW and Hadoop. Actually, that’s the whole point of the example: how even in those cases, you can automatically rewrite the user query to maximize local processing at the data sources and minimize network traffic.
You can see more complex examples in the follow-up post referenced at the end (http://www.datavirtualizationblog.com/performance-data-virtualization-logical-data-warehouse-scenarios/) . All the examples in this second post also require cross-joining data from different sources.
Thanks and best regards !