
If you check the reference logical architectures for big data analytics proposed by Forrester and Gartner, or ask your colleagues building big data analytics platforms for their companies (typically under the ‘enterprise data lake’ tag), they will all tell you that modern analytics need a plurality of systems: one or several Hadoop clusters, in-memory processing systems, streaming tools, NoSQL databases, analytical appliances and operational data stores, among others (see Figure 1 for an example architecture).
This is not surprising, since different data processing tasks need different tools. For instance: real-time queries have different requirements than batch jobs, and the optimal way to execute queries for reporting is very different from the way to execute a machine learning process. Therefore, all these on-going big data analytics initiatives are actually building logical architectures, where data is distributed across several systems.
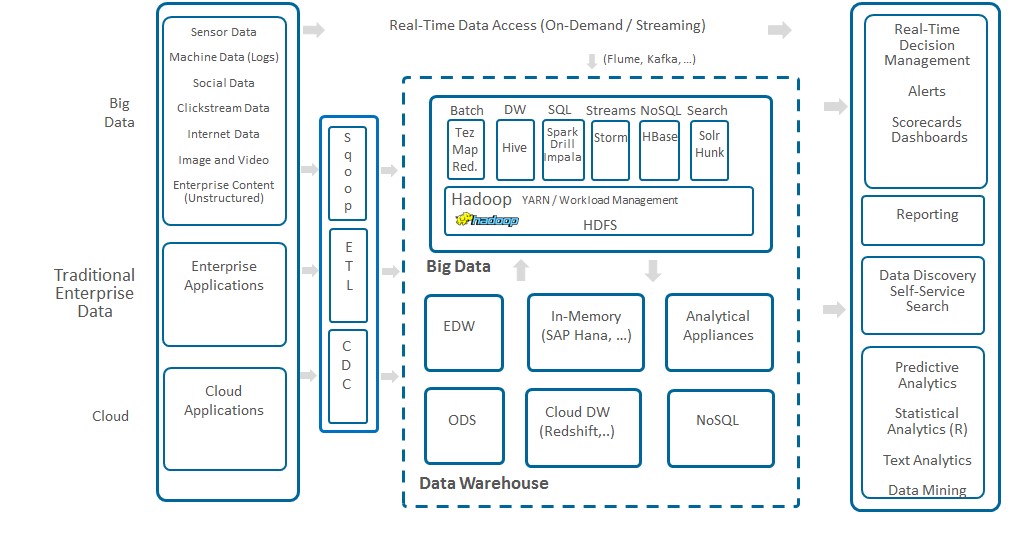
Figure 1: The Logical Architectures of an Enterprise Big Data Analytics Platform
This will not change anytime soon. As Gartner’s Ted Friedmann said in a recent tweet, ‘the world is getting more distributed and it is never going back the other way’. The ‘all the data in the same place’ mantra of the big ‘data warehouse’ projects of the 90’s and 00’s never happened: even in those simpler times, fully replicating all relevant data for a large company in a single system proved unfeasible. The analytics projects of today will not succeed in such task in a much more complex world of big data and cloud.
That is why the aforementioned reference logical architectures for big data analytics include a ‘unifying’ component to act as the interface between the consuming applications and the different systems. This component should provide: data combination capabilities, a single entry point to apply security and data governance policies, and should isolate applications from the changes in the underlying infrastructure (which, in the case of big data analytics, is constantly evolving). Figure 2 shows the revised logical architecture for the example in Figure 1 (in this case, with Denodo acting as the ‘unifying component’).
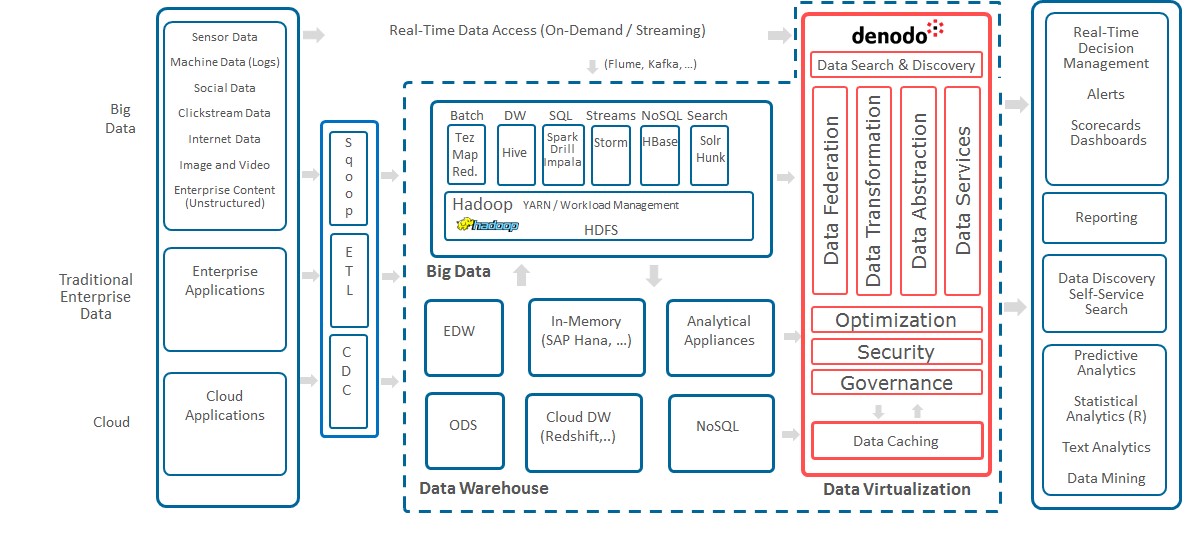
Figure 2: Denodo as the Unifying Component in the Enterprise Big Data Analytics Platform
Four types of software products have been usually proposed for implementing the ‘unifying component’: BI tools, enterprise data warehouse federation capabilities, enterprise service buses, and data virtualization . Nevertheless, in our experience, only data virtualization is a viable solution in practice and, actually, that is the option recommended by leading analyst firms. To understand why, let me compare data virtualization to each of the other alternatives.
Data Virtualization vs BI Tools
Some BI tools support performing joins across several data sources so, in theory, they could act as the ‘unifying component’, at least for reporting tasks. Nevertheless, these tools lack advanced distributed query optimization capabilities. For instance, they typically execute distributed joins by retrieving all data from the sources (see for instance what IBM says about distributed joins in Cognos here), and do not perform any type of distributed cost-based optimization.
In big data analytics scenarios, such approach may require transferring billions of rows through the network, resulting in poor performance. In my previous posts (see for instance here and here), I explained the main optimization techniques Denodo implements to achieve very good performance for distributed queries in big data scenarios: BI tools do not implement any of them.
Another problem with using BI tools as the “unifying” component in your big data analytics architecture is tool ‘lock-in’: other data consuming applications cannot benefit from the integration capabilities provided by the BI tool. In turn, data virtualization tools expose unified data views through standard interfaces any consuming application can use, such as JDBC, ODBC, ADO.NET, REST or SOAP.
Of course, BI tools do have a very important role to play in big data logical architectures but, not surprisingly, it is in the reporting arena, not in the integration one.
Federation at Enterprise Data Warehouses vs Data Virtualization
Some big data and enterprise data warehouse (EDW) vendors have recognized the key role that data virtualization can play in the logical architectures for big data analytics, and are trying to jump into the bandwagon by including simple data federation capabilities. Nevertheless, they support a limited set of data sources, lack high-productivity modeling tools and, most importantly, use optimization techniques inherited from conventional databases and classical federation technologies. These techniques may be useful for operational applications, but will result in poor performance when dealing with large data volumes. Therefore, although they can be a viable option for simple reports where almost all data is stored physically in the EDW, they will not scale for more demanding cases.
Enterprise Service Bus vs Data Virtualization
Some companies aim to expose part of the data in their data lakes as a set of data services. ESBs have been marketed for years as a way to create service layers, so it may seem natural to use them as the ‘unifying’ component. Nevertheless, there are three key problems that we consider that make this approach unfeasible in practice:
- ESBs are designed to process-oriented tasks, which are very different from data oriented tasks. This means they lack out of the box components for many common data combination/ data transformation tasks.
- ESBs do not support ad-hoc queries. Long story short: you cannot point your favorite BI tool to an ESB and start creating ad-hoc queries and reports.
This is because ESBs perform integration through procedural workflows. Procedural workflows are like program code: they declare step-by-step how to access and transform each piece of data. This means you can create a workflow to perform a certain pre-defined data transformation, but you cannot specify new queries on the fly over the same data. Therefore, every new query needed by any application, and every slight variation over existing queries (e.g. aggregating results by a different criteria) will require a new workflow created and maintained by the team in charge of the ESB.
In turn data virtualization tools, in the same way as databases, use a declarative approach: the tool exposes a set of generic data relations (e.g. ’customer’, ‘sales’, ‘support_tickets’…) and users and applications send arbitrary queries (e.g.using SQL) to obtain the desired data. New information needs over the existing relations do not require any additional work. Users and applications simply issue the queries they want (as long as they have the required privileges).
- ESBs do not have any automatic query optimization capabilities. As explained in the previous point, the creator of ESB workflows needs to decide each step of the data combination process, without any type of automatic guidance. This means manually implementing complex optimization strategies. Even worse, as you will know if you are familiarized with the internals of query optimization, the best execution strategy for an operator (e.g. a join) can change radically if you add or remove a single filter to your query. It is simply impossible to expect a manually-crafted workflow to take into account all the possible cases and execution strategies. It is like going back in time to 1970, before databases existed, when software code had to painfully specify step by step the way to optimize joins and group by operations.
In turn, data virtualization systems like Denodo use cost-based optimization techniques which consider all the possible execution strategies for each query and automatically implement the one with less estimated cost.
And finally, Data Virtualization vs …. Data Virtualization
Not all data virtualization systems are created equal. If you choose a DV vendor which does not implement the right optimization techniques for big data scenarios, you will be unable to obtain adequate performance for many queries.
At risk of repeating myself, my advice is very simple: when evaluating DV vendors and big data integration solutions, don’t be satisfied with generic claims about “ease of use” and “high performance”: ask for the details and test the different products in your environment, with real data and real queries, to make the final decision.

- Performance in Logical Architectures and Data Virtualization with the Denodo Platform and Presto MPP - September 28, 2023
- Beware of “Straw Man” Stories: Clearing up Misconceptions about Data Virtualization - November 11, 2021
- Why Data Mesh Needs Data Virtualization - August 19, 2021
Got it, the Modern Data Architecture framework. It is highly complex with lot of moving parts/Open Source..
How doe DV solve the problem ?
Is it not going to add another Layer ?
What about Metadata Management ?
How does DV figure out the Tables/columns dropped or new tables/columns at the source system (True) ?
How does DV handle – CDC ??
What about Data Lineage or Data Governance ?
How do you trace back to 1000s of Data Pipelines – Missing Data ?
Data Auditing mechanism ?
Why not run a Self Service BI on top of a “Spark Data Lake” or “Hadoop Data Lake” ?
Hi Lokesh,
Thank you very much for your questions !. Let me try to briefly answer them. DV helps to solve the problem because:
1) It allows combining data from disparate systems (e.g. data in your DW appliance, data in a Hadoop cluster, and data from a SaaS app) without having to replicate data first. Having all the data you need in the same system is impractical (or even impossible) in many cases for reasons of volume (think in a DW), distribution (think in a SaaS application, or in external sources in a DaaS environment) or governance (think personal data).
2) It provides consuming applications with a common query interface to all data sources / systems
3) It abstracts consuming applications from changes in your technology infrastructure which, as you know, is changing very rapidly in the BigData world
4) It provides a single entry point to enforce data security and data governance policies. For instance, you will get abtsraction from the differences in the security mechanisms used in each system.
Regarding metadata management, a core part of a DV solution is a catalog containing several types of metadata about the data sources, including the schema of data reations, column restrictions, descriptions of datasets and columns, data statistics, data source indexes, etc. This metadata catalog is used, among many other things, to provide data lineage features (e.g. you can see exactly how the values of each column in an output data service is obtained). In the case of Denodo, this information can also be exposed to business users, so they can search and browse the catalog and lineage information.
Regarding the changes in the source systems, Denodo provides a procedure (which can be automated) to detect and reconcile differences between the metadata in the data sources and the metadata in the DV catalog.
Denodo also allows auditing all the accceses to the system and the individual data sources.
In most cases, Denodo does not use CDC because it does not need to replicate the data from the data sources. Denodo can use federation (using the ‘move processing to the data’ paradigm to obtain good performance even with very large datasets), and several types of caching strategies. When the data source allows it, Denodo is also able to tetrieve from the data source only the data that has changed since the last time the cache was refreshed (we call this feature ‘incremental queries’). If needed, CDC approaches can be used to maintain the caches up to date but, as I said before, it is not usually needed. You can check my previous posts (http://www.datavirtualizationblog.com/author/apan/) for more details about query execution and optimization in Denodo
Hope these brief answers have been useful !. Let me know if you have any other question or want me to ellaborate a little more about some of the topics.
Also, if you want to have a more detailed discussion about Denodo capabilities, you can contact us here: http://www.denodo.com/action/contact-us/en/. You can also find useful resources about Denodo at https://community.denodo.com/
I can see that DV can be a powerful layer that can definitely help with accessing data from various sources in most use cases, especially the use cases that involve accessing a snapshot of the data at any given moment.
Can you please explain a bit more on how would the DV layer enable the bottom persona (the Analytics one) reaching the data sets on the other side on the DV layer? The persona in question is exploring the available data, build/test/revise models, so they would need to have access to pretty much raw data.
What other use cases that DV doesn’t support or shouldn’t be used for?
Thanks,
Michael
Hi Michael,
Thank you for your comments !
With DV you can easily access both the original datasets behind the DV layer (at Denodo we call these ‘base views’). You can also create more “business-friendly” virtual data views at the DV layer by applying data combinations / transformations. Both types of views can be accessed using a variety of tools (Denodo offers data exploration tools for data engineers, citizen analysts and data scientists) and APIs (including SQL, REST, OData, etc.). Denodo also integrates with BI tools (like Tableau, Power BI, etc.) and Notebooks (Zeppelin, Jupyter, etc.)
Regarding your last question, DV is a very “horizontal” solution so we think it can add significant value in any case where you have distributed data repositories and/or you want to isolate your consuming users/applications from changes in the underlying technical infrastructure
Hope this helps !
Thanks and best regards,