
Many companies today are embarking on data governance initiatives to avoid drowning in big data. As explained here, data governance tries to establish an upfront agreement regarding:
- What the company needs to track
- How those things should be named
- What attributes should be recorded for each one
- How they are mapped to the information in the real IT systems.
Once you have all these 4 points in place, it is much easier to expose relevant information to business users, while ensuring compliance with the policies of the company.
The three first points above are relatively stable in time. Of course, it takes significant time to identify and standardize business entities, attributes and naming conventions, but once you have done it, they are likely to change at a manageable rate. The fourth point however, is a completely different story: even mid-sized corporations have hundreds of data sources, with overlapping information, different naming conventions and various different technologies. To make things worse, the information landscape is changing faster than ever: the big data trend is increasing the number and type of data repositories, and cloud technology is distributing them even further.
In these conditions, keeping the data governance information up to date can be extremely challenging. But achieving it is critical for the success of the initiative: if users find a different reality in the physical systems than the one described in the data governance infrastructure, they may quickly lose confidence and stop using it.
While data governance tools provide some automatic synchronization mechanisms to try to alleviate this problem, making them work against all data delivery platforms is usually impractical. As a result, a significant part of the work ends up being done manually. Under time pressures, developers tend to prioritize data provision (i.e. making the applications actually work) against checking conformance with the data governance infrastructure, so mismatches can easily appear.
In conversations with our customers immersed in data governance initiatives, an analogy often arises between information governance and documentation of software projects (e.g. UML diagrams). And, how many software projects do you know where UML diagrams and documentation are fully updated?
This maintenance problem can be greatly simplified by using data virtualization as the data delivery platform for business users and applications (see Figure 1). In a nutshell, data virtualization platforms expose ‘logical views’ which can combine and transform in real-time data from one or several physical sources, without requiring data replication. These ‘logical views can expose’ ‘virtual datasets’ compliant with business terminology, while hiding the complex transformations that may be needed to adapt the data in the physical systems to the business conventions. Consuming applications do not need to know where data resides or the technical details (such as query language or data model) of each source system: all data appears to them as belonging to a single system with a consistent query interface.
How can you use your data governance tools with data virtualization? When you define a business entity in your data governance tool (e.g. customer), you can link it to an equivalent logical view in the DV tool with the same attributes and naming conventions (the process can even be automated easily). This logical view will provide a stable endpoint for accessing the data about that business entity, no matter the changes that happen in the IT infrastructure. If today the canonical customer data comes from a CRM system, but next year it comes from a combination of data from Salesforce and a Hadoop-based Data Lake, the change will be transparent for the consuming applications. Notice that the data governance tool still knows where the data of each logical view comes from, and how it is transformed (DV tools like Denodo provide comprehensive data lineage functionalities), but that information is not needed to consume the data.
These logical views also provide a single entry point to enforce data quality checks so when the method to obtain the data of one business entity changes, the checks do not need to be re-implemented. You can also define access control and auditing policies over the logical views, without worrying about the particular security mechanisms supported in each underlying system.
Notice that the definition of the logical views, along with the quality / security checks defined on top of it, constitute a “contract” that developers are enforced to. Therefore, when the implementation of view changes, it is guaranteed that the new implementation will be conformant to the business definitions (naming conventions, attributes, etc.), and will satisfy the data quality checks, without nobody needing to check manually.
This automatic “contract enforcement” is the crucial point that maintains the Governance information synchronized with the data delivery infrastructure: by linking each business artifact (e.g. a business term or entity) with one “run time” artifact (the logical view), we can apply automated checks and synchronizations in a single place, letting the data virtualization tool abstract you from how the data is actually obtained from the myriad of underlying physical systems.
Figure 1 shows a typical way of structuring logical views in a data virtualization platform. The “canonical views” in the second layer represent common, reusable business entities and are the ones that should be linked to stable entities in your business glossary. The logical views in the upper layers combine and adapt the canonical views to create logical data sets adapted to the particular needs/conventions of each type of user / line of business. These views can be also registered and classified in the Data Governance Catalog, along with all the lineage information.
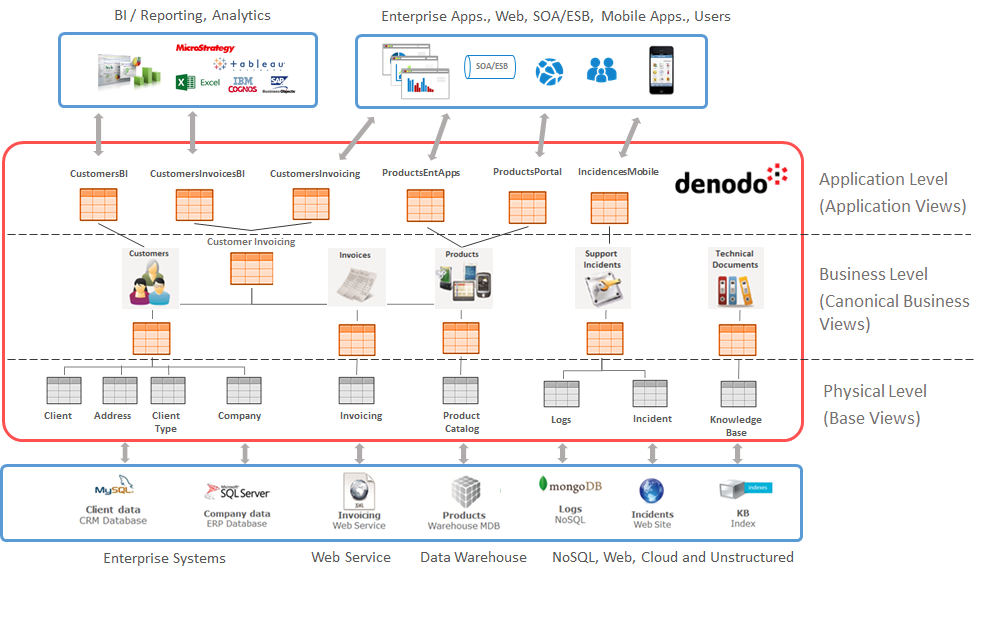
Figure 1: Layers of Logical Views in a Data Virtualization Platform
Once this infrastructure is in place, it is easy to create on top of it information marketplaces for business users, where they can easily locate, share and access information in business-friendly form, while ensuring compliance with all the quality, auditing, and security policies of the company. It is then when the data governance promise can become a reality.

- Performance in Logical Architectures and Data Virtualization with the Denodo Platform and Presto MPP - September 28, 2023
- Beware of “Straw Man” Stories: Clearing up Misconceptions about Data Virtualization - November 11, 2021
- Why Data Mesh Needs Data Virtualization - August 19, 2021
How about the underlying Virtual Cache technology is leveraged to “Schema On Read” like S3:// buckets; Azure Blob; GCP cloud File storage in case of Denodo.
—
Lokesh