
One could almost call it tunnel vision. The way that we consistently hold on to one way in which to fulfil each and every need for information: data copying, transformation and integration in one physical database. We consider it almost a given that we will have to make concessions in terms of flexibility and speed at which data is delivered. After all, it is the only way in which decent query performance can be obtained with the enormous volumes of data that we work with. Right?
No, not actually. Unfortunately, I must disappoint you, because nowadays it is truly possible to do things differently. I would love to show you how in this blog post!
Everything with Just One Approach?
The traditional data warehouse approach is so established, that we don’t know any better than to replicate data numerous times before presenting it for analysis and visualization. After all, we have been taught that we can’t do much without a data warehouse or data mart. In fact, the applications and source systems from which we retrieve data were not created for data analysis. They often don’t include sufficient history, nor – in particular – do they perform adequately. So we revert to the ‘everything with one approach in one data model’. Nice and easy. The only downside is that we continue to hit the boundaries of this approach in terms of supply speed and data volumes. This is why I have advocated, several times, that a hybrid approach – using data virtualization technology – works much better. Where this approach is truly not feasible, because of the need to build history, for example, we then rely on the traditional approach. In all other cases we use data virtualization to virtually unlock and integrate data sources. This results in the logical data warehouse, which is the best of both worlds.
An explanation and arguments in favour of this approach can be found in my previous blog post.
Data Virtualization
In this post I would like to elaborate on the question regarding speed (performance), which is so often directed to me: ‘data virtualization is great, but it does not provide proper performance, right?’ Yeah, how can queries that span numerous data sources perform well with data virtualization, even though the data remains in the source systems? After all, there is a reason why we replicate so many times?
Let’s quickly return to the definition of data virtualization: ‘technology for data virtualization gives information users an integrated, uniform view of all available data, irrespective of the format and storage location of the relevant data, and without replicating such data.’
Data virtualization allows us to unlock data sources much faster and with much more ease. Data virtualization platforms have developed tremendously and include extensive functionality for performance optimization. At Kadenza we use the Denodo Platform for data virtualization. The examples in this post were derived from Denodo practices, but naturally other tools will offer similar functionality.
Smart Retrieval
Firstly, these types of platforms ensure that only the data that is needed is retrieved from the source systems, and records are therefore a thing of the past. Data virtualization is all about ‘smart retrieval of data’ instead of ‘first retrieving everything, then filtering and joining’. After all, the less data needs to be processed, the faster the process will be. The data virtualization platform’s query optimizer breaks down the (SQL) search – which comes in from Tableau or Cognos BI, for example – into sub selections. Each of these sub-selections is sent through to the data source responsible for providing the data for that sub-selection. In the Denodo Platform this is called full aggregation pushdown. The emphasis here is placed on limiting and filtering when selecting data from the source. The data is only retrieved if such retrieval is strictly necessary for the query. Since large volumes of data are not often required for most user queries, it does not usually take long for these sub-selections to be retrieved from the data sources and to be combined to form the required data sets.
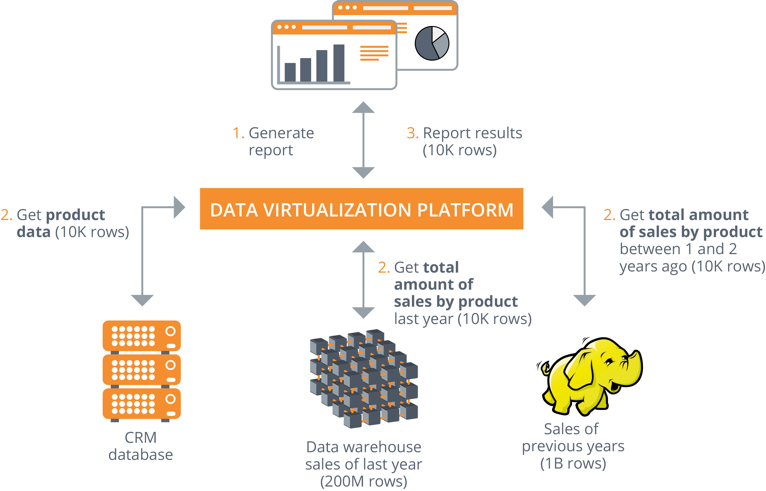
Execution Plans
I can already hear you saying ‘Yes, but… It is hardly ever that simple! Sometimes one must combine large data sets or the joins are complex.’ That is correct. Even in such more complex situations, the data virtualization platform offers various execution plans so that the answer can be derived in a way that is smart and efficient. For example, the Denodo Platform has the following techniques available:
- Full aggregation pushdown: the precise records that are required are filtered and retrieved from the source, from the correct aggregate level.
- Partial aggregation pushdown: the necessary join and aggregation on the same level are carried out with several retrieved and filtered data sets on the data virtualization platform.
- On-the-fly data movement: a temporary table is created in the data source from which the largest data set must be retrieved and the join is carried out in the database, in other words, directly ‘next to’ the largest data set.
The platform automatically activates these techniques when necessary. Moreover, you can actually see how the platform deals with this (which technique is used when) and can adjust where needed. In actual practice we see that query performance in this case is the same as with a physical data warehouse.
Practical Example
I will demonstrate this by way of a practical example. We will compare the performance of a logical data warehouse and a physical data warehouse when the same queries are run. Both data warehouses contain the same (volume of) data, only the architecture differs. The physical data warehouse consists of a single database in which all data – that is retrieved from the source systems and transformed – is stored. The logical data warehouse, on the other hand, supplies data via a data virtualization layer. It appears to be one data source, but the data is located in several source systems and is retrieved ‘on-the-fly’. The physical data warehouse, on an IBM PureData (formerly Netezza) appliance, contains 292.4 million records. This is just as much as in the three separate databases of the logical data warehouse.
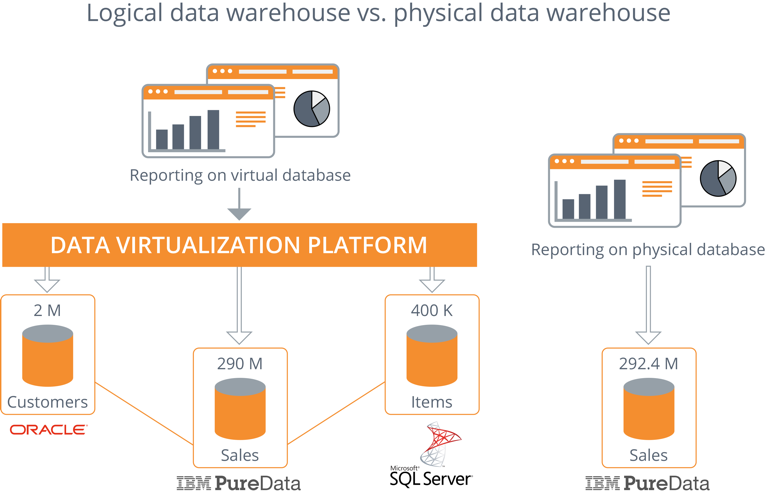
The same queries are then run on both data warehouses (physical and logical) for performance measurement purposes. When we compare the results, we notice that the performance between the two solutions does not differ to a significant extent:

Depending on the relevant query, the data virtualization platform determines the most efficient method for rapid retrieval and joining of the required data. Although it is possible to influence the method that is used, it seems superfluous in actual practice.
Data Caching
Apart from the methods for performance optimization, already mentioned, the data virtualization platform also offers the data caching option. Since this option allows for data to be stored once again, it is actually contradictory to the basic principles of data virtualization. However, sometimes you don’t have any other choice. For example, if an application cannot be consulted by BI applications during office hours, or if the query does not process the data source fast enough. In such cases, caching can be activated instead of the long-standing method of replicating data to a physical data warehouse. Caching can be set for a specific period of time or for a specific sub-selection of data.
Conclusion
Indeed. The conclusion: ‘stop with the consistent, yet ill-considered copying of data to a physical data warehouse for performance-related reasons!’ One can also achieve excellent performance-related results with a logical data warehouse, where data sources are virtually connected. Without having to make concessions in terms of performance, the utilization of data virtualization affords you flexibility, real-time availability of data, a much simpler architecture, management simplicity and a substantially higher supply speed. In other words, stop the endless ETL process and determine the best approach per data source: physical or virtual integration. The current generation of data virtualization platforms, such as Denodo, provides all the required functionality in one integrated platform.
The data warehouse then becomes a multi-platform environment. The traditional, relational data warehouse will continue to exist, but only for the data that absolutely requires this approach. Other data can be linked much faster and easier by way of data virtualization. Without any loss of performance!
Here is the substantiation for the figures in this post.
Here you can find more background information on performance in various data virtualization scenarios.
This blog was penned by Jonathan Wisgerhof, Senior Architect, Kadenza
www.kadenza.nl
- How Much Time Could Your Company Save If You Said Goodbye to Data Migration? - January 30, 2019
- Get Ready for the General Data Protection Regulation (GDPR), with Data Virtualization - May 24, 2018
- Data Virtualization is a Revenue Generator - September 20, 2017