
While companies focus on obtaining a holistic view of their data to make insight-driven decisions, chief data officers struggle with the uncontrollable growth of hundreds of data silos and different information systems that prevent them from delivering true business value. If only they could find a remedy.
Management information systems: the start of the disease
It all began in the 1990s with the rise of the enterprise resource planning (ERP) platforms. These applications were designed to achieve greater business efficiency by integrating and automating main financial, administrative, and logistical processes in one single suite and database. Today, we are seeing how all of this worked out.
Instead of having one ERP, many companies implemented multiple ERP suites with different one in each division or country. On top of those, many inherited more ERP applications from mergers and acquisitions, different than the existing ones. Now, with the rise of the cloud and software-as-a-service platforms, the information silos virus has exploded, since it’s easier and cheaper to purchase these applications without corporate approvals.
Furthermore, other departments picked and chose also different tools for different purposes and data sets without enterprise-level oversight. As a result, besides having one (or many) ERPs for finance, administration, and logistical processes; very probably the company now has a CRM for the marketing and sales department, an MRP for manufacturing processes management, an HRM system for human resource, a document management solution, etc.
Far from operational excellence
The first consequence of this application silos disease is a lack of operational excellence.
Value creation is a horizontal process, and the key to gaining a competitive advantage is optimizing the flow of products and services through the value streams that flow horizontally through all departments to the customers (Figure-1). The main idea is to maximize customer value while minimizing waste in the whole value creation process. In fact, this is the primary purpose of any organization, and profit is the result of doing so efficiently and effectively.
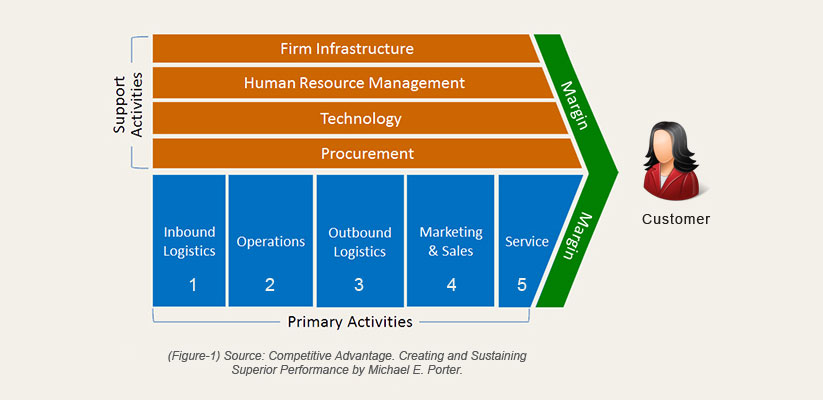
However, different systems in different departments allow each one to manage its own functional or vertical processes. In turn, those isolated systems fail to manage cross-functional processes needed for collaboration among departments to create and deliver value to the customers. In other words, systems (and metrics) are usually designed to optimize departmental or individual activities rather than across the organization as a whole.
This means that we may often find a lot of waste and non-value added activities along the value chain of many companies, such as waiting among departments, over-processing, overproduction, defects and inspections, excessive inventories or non-utilized talent, which are difficult to detect and eliminate due to the lack of a common information structure that connects processes and departments horizontally. This operational inefficiency costs time and money. But in the end, who cares; the customers pay the bills, right?
Data silos: The virus keeps spreading on the information side
Since different departments or stake holders use separate sets of data, on the information side no one possesses neither the “big picture”. Companies aim to give their employees access to data in real time with no departmental or geographic boundaries; however, most of them have difficulties even collecting this data in a consistent and timely fashion.
For example, it is common to see an organization with a system that tracks sales and pricing by product and another one that tracks sales information by geography. Even commonly used financial information, such as gross margins to measure profitability, is calculated differently from one business unit to another. We should not be surprised that this happens, since some of these companies obtain their information from more than 800 data marts.
The lack of data consistency is a bigger problem than most people think. Data silos drag down sales and profits. Compiling information about the business from multiple systems, can take up to a week or even months, in some cases. This means that managers have to make decisions based on relatively old data. Financial consolidation at international companies, with the added complexity of multiple currencies, legislations and so on, is a nightmare when using many local heterogeneous systems or different implementations communications via Excel (yes, believe it!). Seemingly simple questions, such as how much the company is spending on marketing across its different businesses or countries, are difficult to answer. Without a consistent view of the enterprise, executives struggle with decisions on matters like the size of sales and service teams to be assigned to particular operations.
In order to get rid of the data silo problem, companies would have to build an all-inclusive central data warehouse, servicing the entire enterprise; but very few have done it. The organization and integration of all data as well as the design principles requires a great deal of work. As businesses continue to change through mergers and global expansion, today’s data warehouse will be out of date tomorrow. Additionally, there are political issues involved; not all departments want to depend on a central data warehouse supported by a centralized information systems staff for their data-analysis needs.
With the outcome of big data and NoSQL stores, this silo problem gets even exacerbated, as nowadays it is common to see companies deploying a BI architecture with a Hadoop store, several enterprise data warehouses, and some analytical appliances.
In this scenario, some IT departments have tried to streamline at least the number of data warehouses. Nevertheless, as the company grows, data warehouses and data marts continue to be developed and deployed, perpetuating rather than overcoming the data silo issue. Thus, the worldwide disease at large organizations expands.
Get an antidote with data virtualization
Modern data management practices like data virtualization provide IT departments the chance to integrate any data source in an agile way and deliver complete and high-quality information to the business more rapidly and with fewer resources than traditional data integration approaches.
Data virtualization can break down data silos by federating multiple physical sources, either operational enterprise systems or informational warehouses. This technology combines disparate data sources into a single “virtual” data layer that provides integrated data services to consuming applications in real-time regardless of where data resides. By implementing a virtual data integration layer between data consumers and existing data sources, organizations can avoid physical data consolidation and storage of replicated data (also a big waste). Consumption is done on demand from the original data sources (structured or un-structured), including transaction systems, operational data stores, data warehouses and marts, big data, external data sources, social media and more.
This approach provides a logical consolidation of warehouses by creating an integrated view across them, using abstraction to rationalize the different schema designs (the so called “logical data warehouse”), that can also be applied to specialized analytical appliances, big data and NoSQL sources. Thanks to data virtualization, organizations can rapidly combine data, for example, from the supply chain and financial warehouses or two marketing data warehouses after a merger.
So, we could say that data virtualization helps to easily “eradicate” data silos, unlocking access to them, improving analytic capabilities, and providing a holistic view of a company in an era where new data sources and compliances just keep appearing.
Back to business
From the operational excellence perspective, data virtualization can help manage, not only functional, but also cross-functional processes. For example, since data is more accessible through rapid integration, office or service processes across the entire organization can be more easily designed and automated by the existing information systems. Information management becomes simpler and more accurate. The dream of being able to make information flow more efficiently and effectively through the whole value chain becomes more of a reality.
On the informational side, by tracking and adding visibility of the data along the entire value chain, data virtualization helps manage horizontal value streams through a system-wide view of how value is created in the company. With that insight, companies can organize themselves around the “value streams” that encompass the resources needed (no more, no less) to fulfill orders for a product or service.
The impact of data virtualization can be very strategic. Eliminating waste horizontally along the entire value stream, instead of only at isolated or departmental points, results in less complexity, less lead time, lowers costs, increased revenue, improved products and services,… and happier customers.
Seems like the business world can be saved after all. What do you think?
- Data Movement Killed the BI Star - May 12, 2016
- Data Silos: Beat the Gremlins! - October 28, 2015